ANR-XTCOVIF: Publications and Datasets
Publications and Papers
- Panagopoulos, G., Nikolentzos, G., & Vazirgiannis, M. (2021). Transfer Graph Neural Networks for Pandemic Forecasting. In Proceedings of the 35th AAAI Conference on Artificial Intelligence. Code available: https://github.com/geopanag/pandemic_tgnn
- Guo, Y., Xypolopoulos, C., & Vazirgiannis, M. (2021). How COVID-19 Is Changing Our Language: Detecting Semantic Shift in Twitter Word Embeddings. arXiv preprint arXiv:2102.07836.
Twitter Datasets
Part 1: Multi-Lingual Dataset
We started gathering tweets regarding Covid-19 in England on February 28, when the confirmed cases in the UK were only 15, and we continue gathering until now. We started from England because english is the easiest language to extract knowledge from.
We used the Twitter REST API for the most popular tweets, and have gathered up to now 115,776 unique tweets and 18,808,510 retweets of these tweets. The query we use to collect the tweets is: (CoronaVirus AND England) OR (CoronaVirus AND UK) OR (COVID AND England) OR (COVID AND UK) OR #CoronaVirusEngland OR #EnglandCoronaVirus OR #CoronaVirusEn OR #CoronaVirusUK.
About a week later, we started gathering respective data for France, Italy, and Spain and more recently for Germany and Greece. The number of tweets and retweets that we have collected for each country so far is illustrated in the following Table:
| Country | Tweets | Retweets | |
|---|---|---|---|
| France | 21.705 | 6.212.469 | |
| Italy | 29.361 | 8.415.416 | |
| United Kingdom | 115.776 | 18.808.510 | |
| Spain | 17.871 | 16.396.296 | |
| Germany | 2.147 | 9.922.565 | |
| Greece | 1.136 | 5.633.144 |
These tweets do not include only country-specific languages, e.g., french for france, as we have also gathered international tweets that may refer to the spread of COVID-19 in France. Hence each set of tweets is multilingual.
1. Analyzing Tweet/Retweet/Favorites Rate
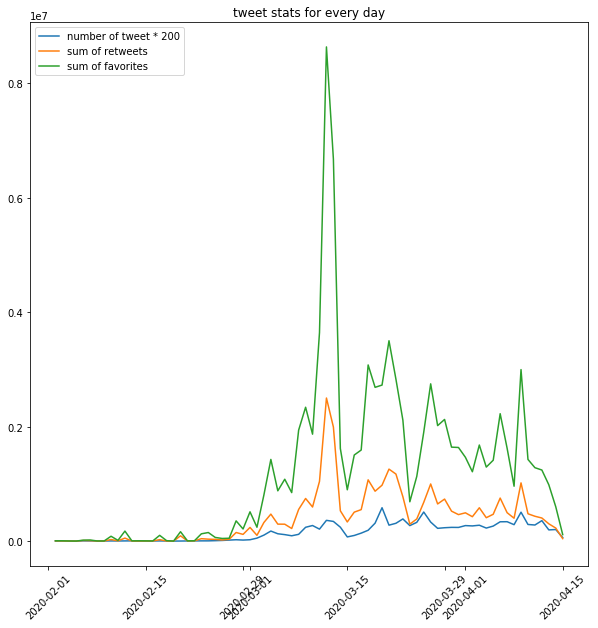
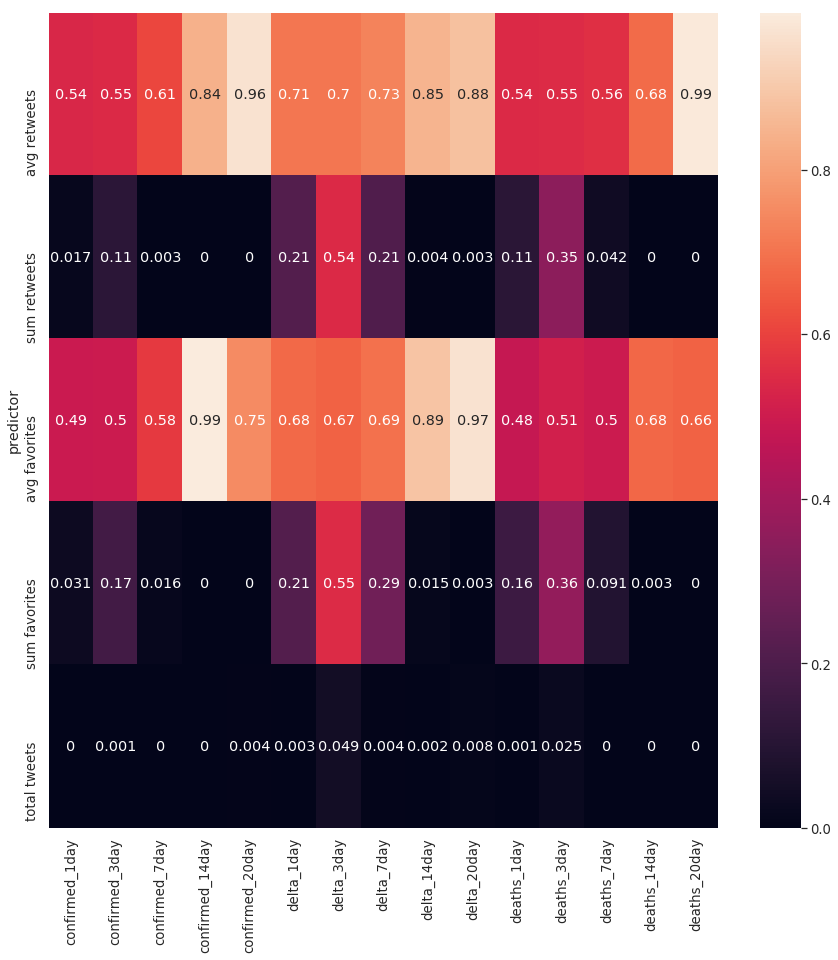
We first study the tweeting activity patterns of the users with regards to the pandemic. The left Figure below shows the number of tweets, retweets and favorites as a function of time. Clearly, users became more active from March 2020. A very large number of retweets was posted between March 10 and March 13. The right Figure shows the p-value derived by computing granger causality between the time series of the left Figure and the time series that emerge from three actual pandemic metrics, namely the number of confirmed cases, the daily increase/decrease in the number of confirmed cases (delta), and the number of deaths. The results indicate a strong relationship between the number of tweets produced (last row of heatmap) and the pandemic metrics.
|
 |
2. Graph-based Identification of Clusters of Tweets
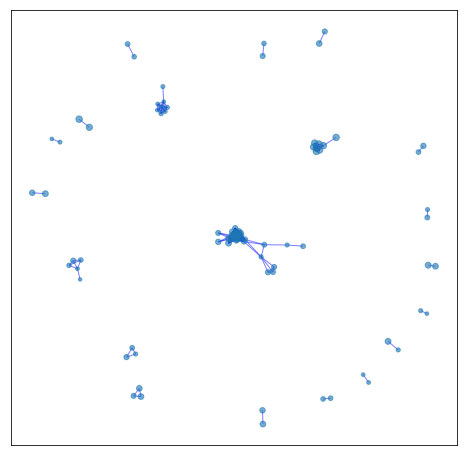
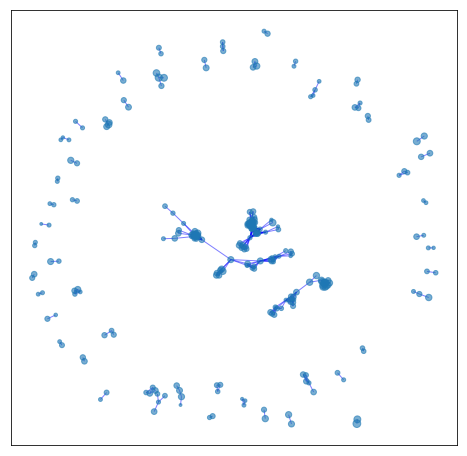
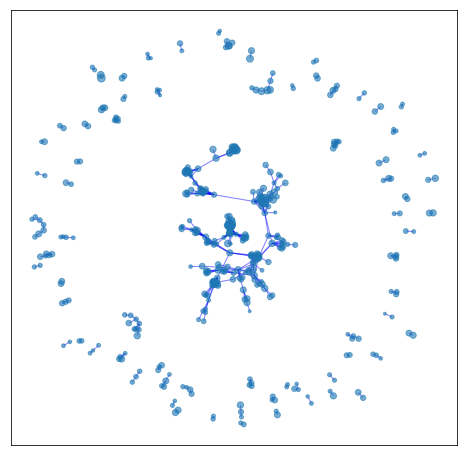
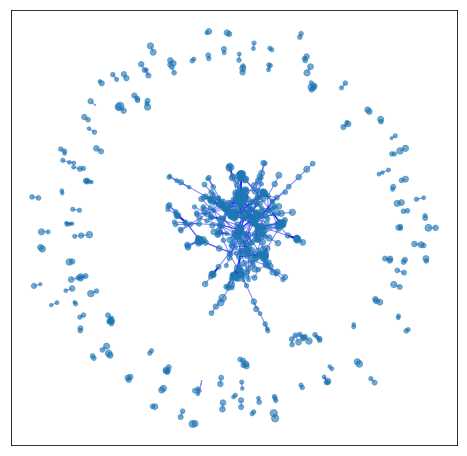
Given our set of unique tweets, we create a graph where nodes correspond to tweets and two nodes are connected to each other by an edge if the two tweets were both retweeted by at least a common user. Therefore, the graph does not model the textual similarity of the tweets. The increase in density of the emerging graph over time indicates how twitter activity increased and how information started to spread as the pandemic unfolds. The following six Figures show the cumulative graph of tweets of the UK dataset up to a certain date (i.e., March 3). As we can see, in all cases, the graph consists of several components which correspond to different topics and different opinions expressed by the users.

|
|
|
| February 17 | February 22 | February 29 |

|
|
|
| March 1 | March 2 | March 3 |
For example, a more detailed view of the third graph (i.e., February 29) is given in the Figure shown below. As we can see, some of the biggest components of the graph correspond to tweets of a single user (i.e., @BBC). We also illustrate the most frequent terms of the tweets posted by these users. Interestingly, some of the tweets contain news posted by official organizations (such as BBC and DHSC of the UK government), while others correspond to personal opinions about the origin of the virus and the policies around COVID-19.
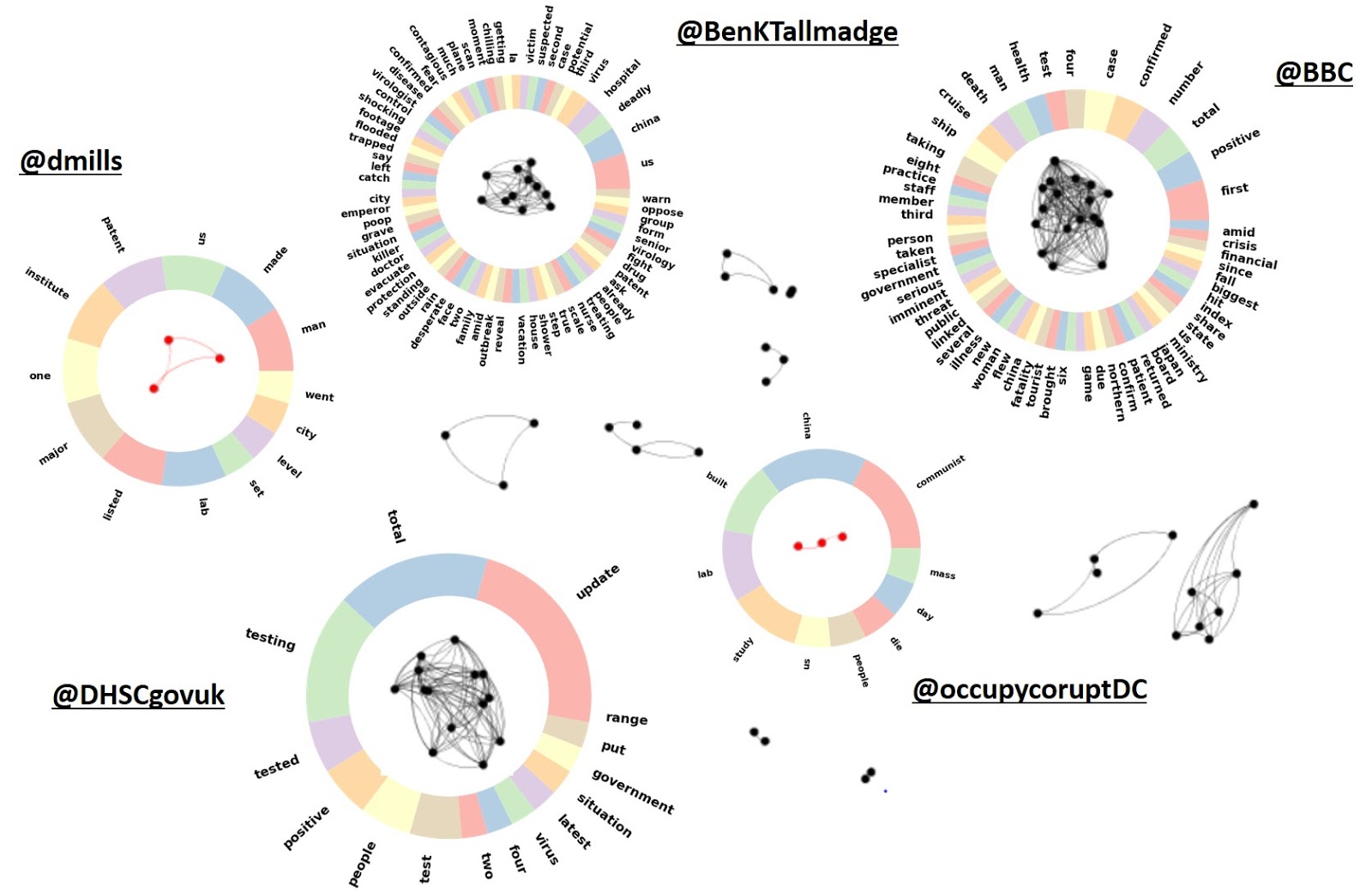
Individual components and their most frequent words on February 29
After the 1st of March, however, COVID-19 has become a very central issue on Twitter (as shown also in Figure 1) and hence the relevant tweets’ spread increases. This translates into many users following or resharing a diverse set of opinions/news coming from different sources. Thus, a giant component is now formed, where the most popular opinions are gravitated in. Still, there are numerous individual components around it, but they mostly represent tweets of a certain person about an issue that is not (at least yet) of wide concern.
In order to discern any type of opinion groups inside the main component, we extracted it and applied a community detection algorithm based on weighted modularity. We next computed the word cloud of the most frequent hashtags utilized in the tweets of each community. The word cloud is shown below.
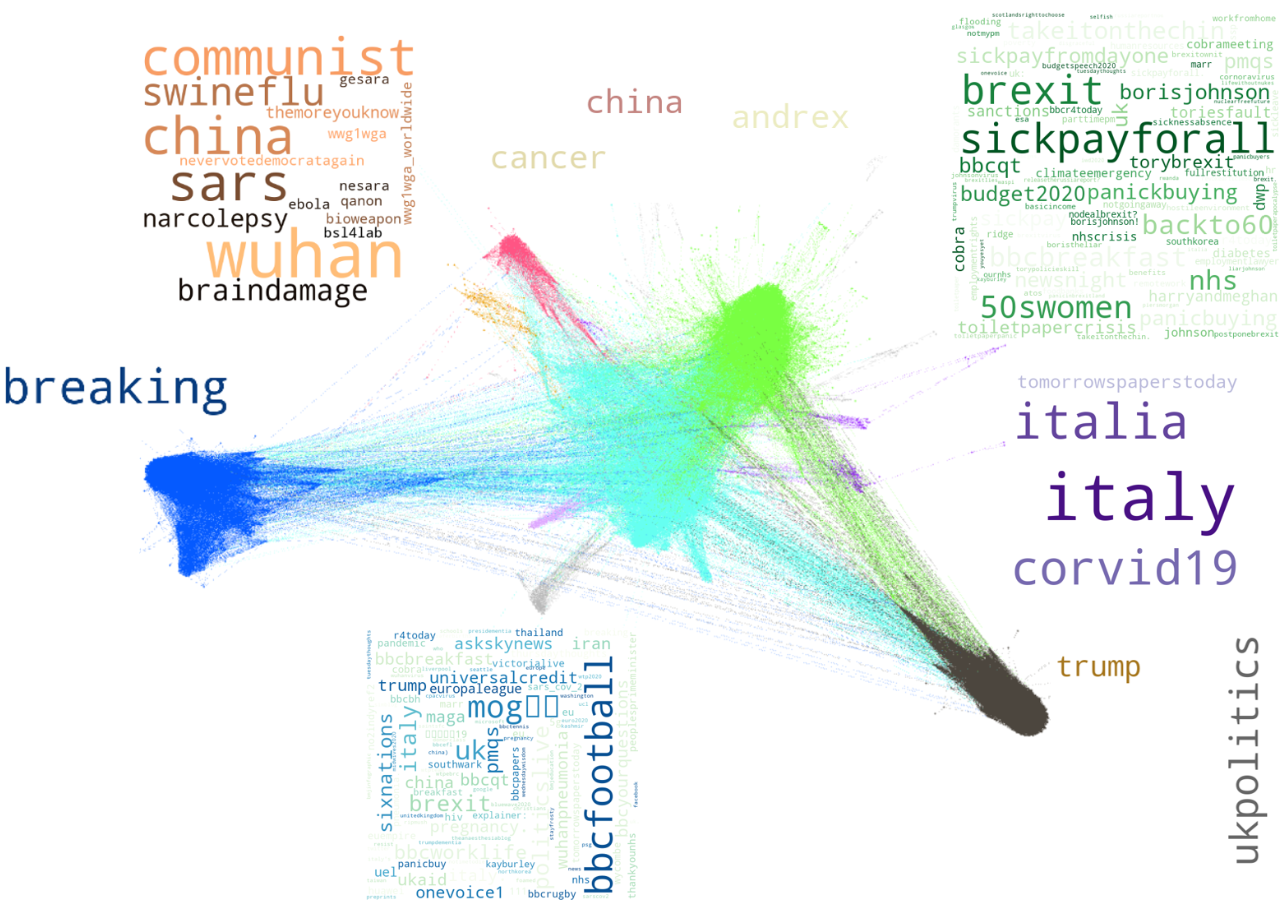
Communities of the tweet graph on March 10th and their most frequent hashtags
One can see that modularity separated successfully some opinion clusters hidden within the graph. More specifically, the blue cluster consisted mostly of official news sources, where the frequent hashtags included “breaking”, ”covid-19”, “coronovirus” etc. These posts are mainly retweeted by neutral users following the news. The purple cluster concerns news around the spread of the virus in Italy, which at that time, was one of the most important subjects since Italy was severely hit by the virus. The green cluster is mainly about the policies of Britain against COVID-19, including the demands for sick pay, the complains about panic buying, the concerns around the NHS, and the Cabinet Office Briefing Rooms (COBRA) meetings that were taking place by the UK officials to plan the UK policies against the pandemic. The cyan cluster contains diverse information from multiple perspectives, that is why its position is central in the graph, and is thus shared by many communities. The most interesting community is probably the orange one (upper left), where we see lots of references to china, and opinions related to conspiracy theories (e.g., #themoreyouknow) that have been adopted by a significant portion of the public since then. More specifically, we find tweets mentioning that the virus was developed in the bsl4 lab in Wuhan, as a bioweapon. Moreover, some tweets share content that is popular amongst the right wing US population, such as political commentary (“#communist #china”), reference to the National Economic Security and Recovery Act (#nesara https://en.wikipedia.org/wiki/NESARA) and support to the conservative party (e.g. #nevervotedemocratagain).
3. Evolution of Hashtags
We next identify which are the most popular hashtags among Twitter users and how these hashtags evolve over time. Specifically, we generate an evolving word cloud which shows the most frequent hashtags for each day from March 2020 to April 2020. The size of a hashtag in the word cloud indicates its popularity. The results for the datasets related to the UK and France are shown in the following two Figures.
 |
 |
We can see that we can get a general idea about the major events related to COVID-19 just by looking at these hashtags. At the early stages of the pandemic, the uncertainty due to the virus caused people worry and stress, therefore hashtags such as #coronavirusoutbreak, #panickbuying and #toiletpapercrisis became very popular. Then, on March 12th, when the COBRA meeting took place, the top trend became #cobrameeting, followed by #herdimmunity on March 16th, shortly after the UK government announced that they will rely on herd immunity to slow the spread of COVID-19. The hashtags #lockdownuk and #londonlockdown took over on March 19th, the day the lockdown decision was announced. Other major events include #borisjohnson on March 27th, the day Boris Johnson was tested positive and #queensspeech on April 5th, the day the Queen gave the coronavirus speech. We also see that as time evolves, people start to calm down, leading to more positive tweets. Starting from April, positive hashtags such as #wearetogether, #outsmartepidemics, #clapforcarers, #protectthefrontline have become increasingly popular.
4. Evolution of Vocabulary
Besides hashtags, we also study how the vocabulary of the tweets evolves as a function of time. Specifically, the following two charts illustrate the 20 terms with the highest cumulative frequencies over time in the UK and France datasets.
 |
 |
Again, it is clear that the most frequent terms are related to the major subevents of the pandemic. For instance, we can see that the term “macron” appears in the list of the most frequent terms on March 12th, the day when the French President Emmanuel Macron announced a series of measures to slow the spread of COVID-19. On March 15th, the term “confinement” became one of the most frequent terms. The next day, President Macron announced a 15-day lockdown. Similar trends are observed in the chart generated by the tweets of the UK dataset.
Part 2: Real-time Twitter Dataset
In parallel, we started collecting a more broad category of tweets using the Twitter Streaming API. In this case, our filters are focused on tweets that include the hashtags “covid19” and “coronavirus”. The objective of this dataset is to collect a huge, coherent, body of texts related to the virus and use it for further research tasks such as training word embeddings. Up to this point, we have collected over 160m tweets, averaging 3m tweets per day.