Large scale analysis of mobility data and language during the COVID19 pandemic
Semantic Shift in Vocabulary due to COVID-19
Paper: https://arxiv.org/pdf/2102.07836.pdf
Introduction
The COVID-19 pandemic is the major health crisis of our time, and has changed many aspects of the world. Among others, COVID-19 is likely to have had some impact on the meaning of words in natural languages. Indeed, the meaning of a word can change and shift over time as a consequence of major events such as pandemics. Therefore, one of the objectives of this project was to study the semantic stability of words during the COVID-19 crisis.
To explore the semantic stability of words, we measured how the respective embedding vectors have been influenced by the pandemic. More specifically, we collected a set of COVID-19 related tweets for three consecutive months after the outbreak and used distributional semantics to generate independent embedding spaces for each of these three months. The emerging embedding spaces were then compared with a general-purpose Twitter word embedding model generated from tweets collected before the pandemic. In addition, the three generated embedding spaces were also compared to each other to detect semantic shift of vectors over time.
Dataset
The tweets used for building the COVID-19 related word embedding models date from April 2020 to June 2020. This dataset corresponds to a large and coherent corpus consisting of small pieces of text related to the pandemic. In this case, we focused on tweets that included the hashtags “#covid19” and “#coronavirus”. Through Twitter’s streaming API, we extracted tweets in English language marked with either or both of the two above hashtags. Given that the pandemic has been the center of global attention ever since its outbreak and that the situation is evolving rapidly on a daily basis, we have reason to believe that there would be detectable semantic shifts even over the short periods of single months. Therefore, we constructed monthly word embeddings for each of the months April, May and June. After removing retweets and quoted tweets, the dataset consists of 35 million unique tweets for the month of April, 21.0 million for the month of May and 13.4 million for the month of May. The total size of vocabulary is 0.3 million terms. We use pre-trained word embeddings twitter-200 from open-source package gensim to serve as a reference semantic space for Twitter language before the outbreak of COVID-19. This embedding is trained on 2 billion tweets dating before 2017, with a vocabulary size of 1.2 million.
Methodology
Before learning word representations, each tweet was pre-processed. The following steps were applied:
- Conversion to lowercase: All letters in each tweet were converted to lowercase.
- Removing URLs and mentions: We removed all mentions and URLs appearing within the tweets.
- Removing emoji symbols and special characters: We removed all emoji symbols and special characters, except hashtag symbols #.
- Removing stop words: Stop words are frequent words that carry little information, such as prepositions, pronouns, and conjunctions. We removed words from the list of English stopwords in the NLTK library.
- Removing short tweets: Extremely short tweets, i.e. tweets with fewer then 10 tokens in total, do not contain meaningful content in most cases and were therefore removed.
To generate word embeddings, we used the open source implementation of Word2Vec in the gensim package. We removed words that occur less than 10 times and applied the Skipgram architecture. We chose a window size of 5 and dimensionality of 200 for the word vectors. We initialized the word vectors of month April randomly and used tweets from April to train them. Once the training procedure has been completed, we used the learned embeddings to initialize the word vectors of May. Likewise, we initialized the word vectors of June with the trained vectors of May.
Note that due to the rotational invariance of cost functions in the Word2Vec training algorithm, the separately-learned embeddings are placed into different latent spaces. This does not affect pairwise cosine similarities within the same embedding space but prohibits the comparison of the same word across context and time. Therefore, to detect semantic shifts, we followed a two-step procedure: (1) we first aligned the different word embedding spaces, and then (2) we applied two-way rotational mappings.
With regards to the first step, having trained COVID-19 related word embeddings for each of the three months (April, May and June), we decided to align the three embedding spaces based on embeddings of general-purpose terms that are not related to COVID-19. During the alignment process, we made two simplifying assumptions: First, we assumed that the spaces are equivalent under an orthogonal rotation. Second, we assumed that the meaning of the most frequent words in the general vocabulary does not shift over time, and therefore, their local structure is preserved. The second assumption is also related to ”the law of conformity” [Hamilton et al., 2016], which states that rates of semantic change scale with a negative power of word frequency. To align the learned embeddings to the same coordinate axes, we used orthogonal Procrustes [Schönemann, 1966]. Specifically, we defined W0 ∈ Rd×|V| as the matrix of the 1000 most frequent words in the base embedding model. We defined W ∈ Rd×|V| to be the matrix of the same 1000 words in the target embedding model. We aligned W to W0 while preserving cosine similarities by optimizing the following problem:
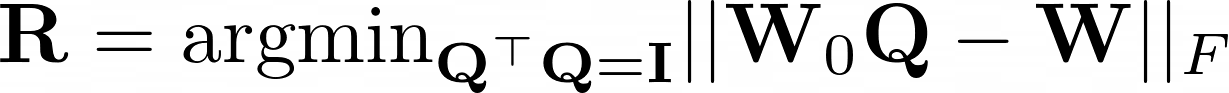
We solved this optimization problem by an application of singular value decomposition which gave us the best rotational mapping between the two embedding spaces.
After aligning the embedding spaces, we could directly measure the stability of words by comparing their embeddings. The more stable a word is, the less semantic displacement it has undergone in the new context. However, we found that directly computing the cosine similarity between a word’s representations in the different spaces is not a good measure of stability since similarities were low on average, indicating that one-way rotational mappings are not of high quality. Hence, we instead used two-way rotational mappings, which led to a significant increase in the average similarity. We observed that words were generally mapped close to their starting orientations when mapped back into their original space. We then define the “stability” of a a word w as
follows (inspired by [Azarbonyad et al., 2017]):
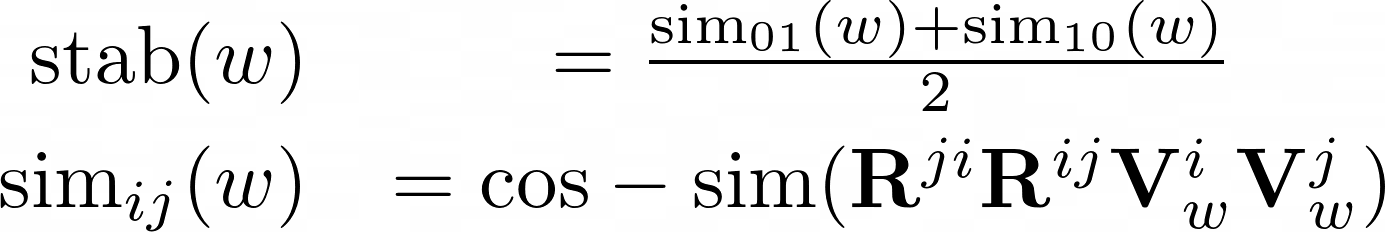
The stability of a word using this measure equals to the similarity of its vector to its mapped vector after applying the rotational mapping back and forth.
Results & Discussion
We next present the obtained results. Specifically, we first present the stability distributions which indicate the existence of semantic shifts. The following Figure shows the stability distribution of words before and after COVID-19. For every word, we compute its stability between the pre-COVID-19 model and each of the three post-COVID-19 models, taking the average value as its final stability measure.
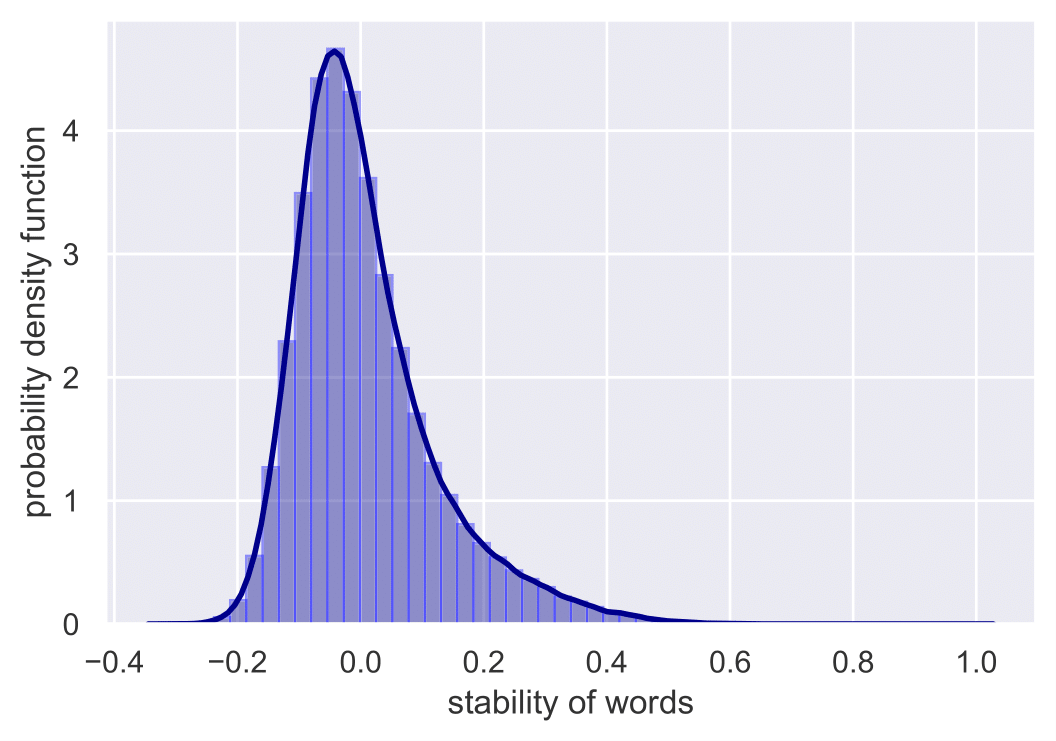
We see that the distribution is skewed, centered around 0 and tilted towards the right. The Figure shown below illustrates the stability distribution of words during the months April, May and June. For every word, we compute separately its stability between April-May and May-June, taking the average value as its final stability measure.
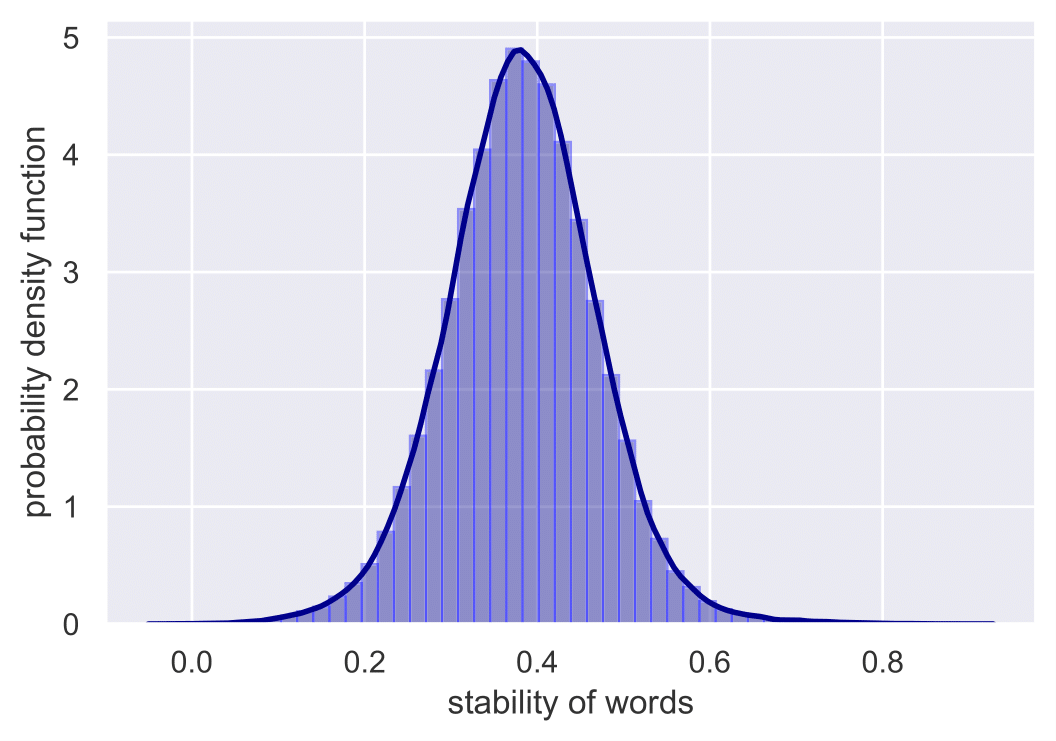
In this case, we can see that the distribution is almost normal, centered around 0.4 and not tilted. The absolute value of the stability measure does not make sense, considering that the alignment cannot reach perfection even after optimization. Nonetheless, the shapes of the distributions indicate that there exists both cross-corpora and diachronic semantic shifts. Otherwise, the distributions should be extremely left-skewed and concentrated around a relatively high value. Comparing the two distributions, we can reach the conclusion that the semantic change across corpora is more significant than that over monthly time periods.
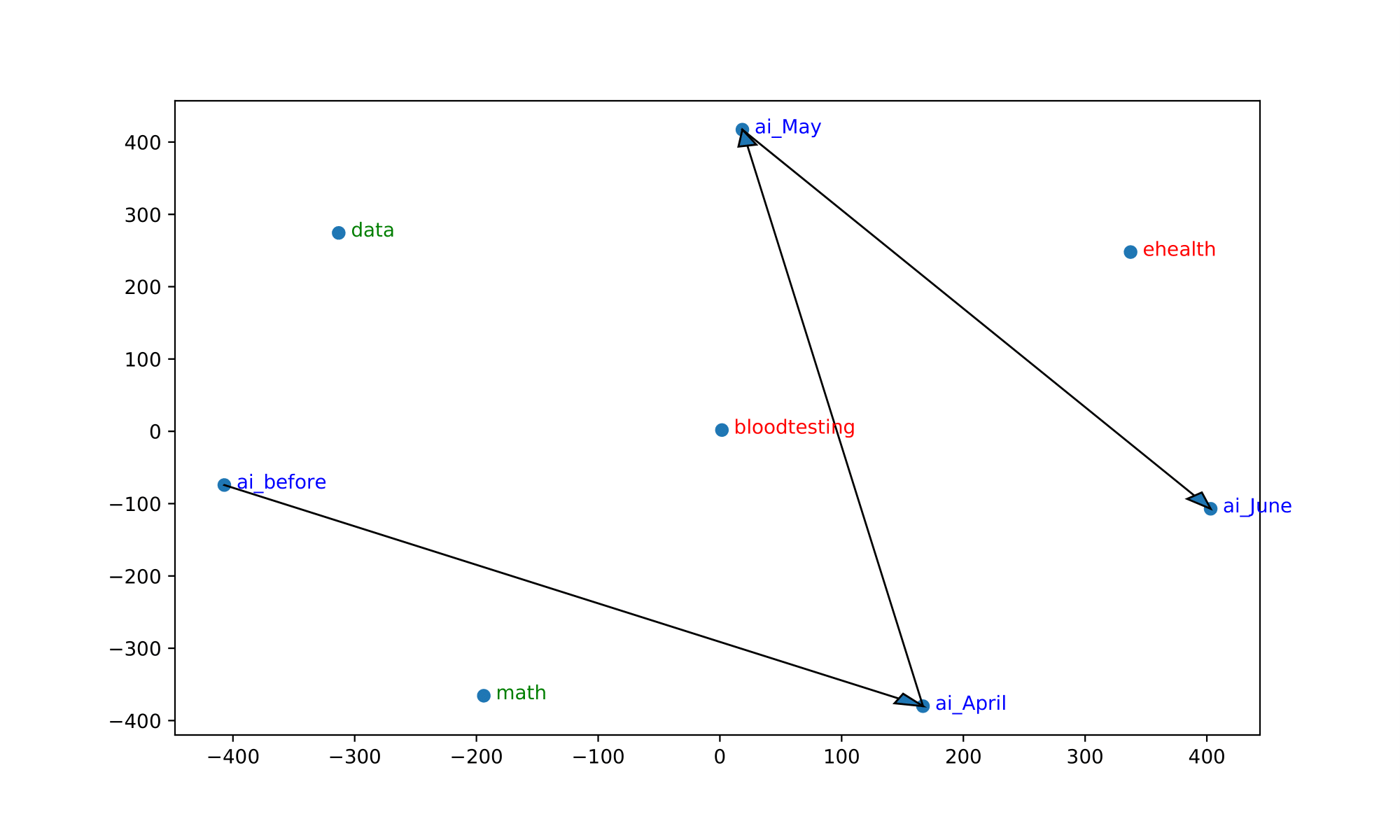
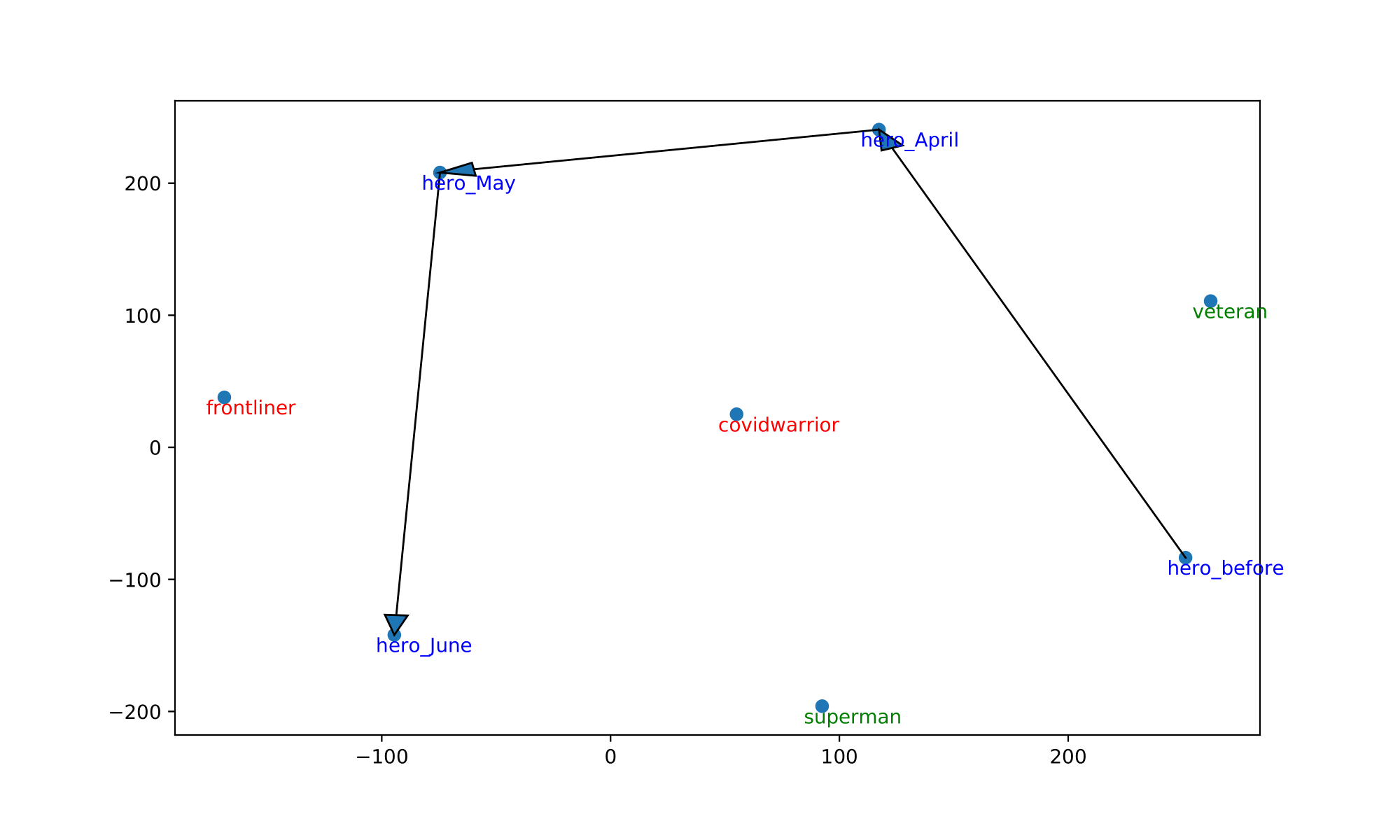
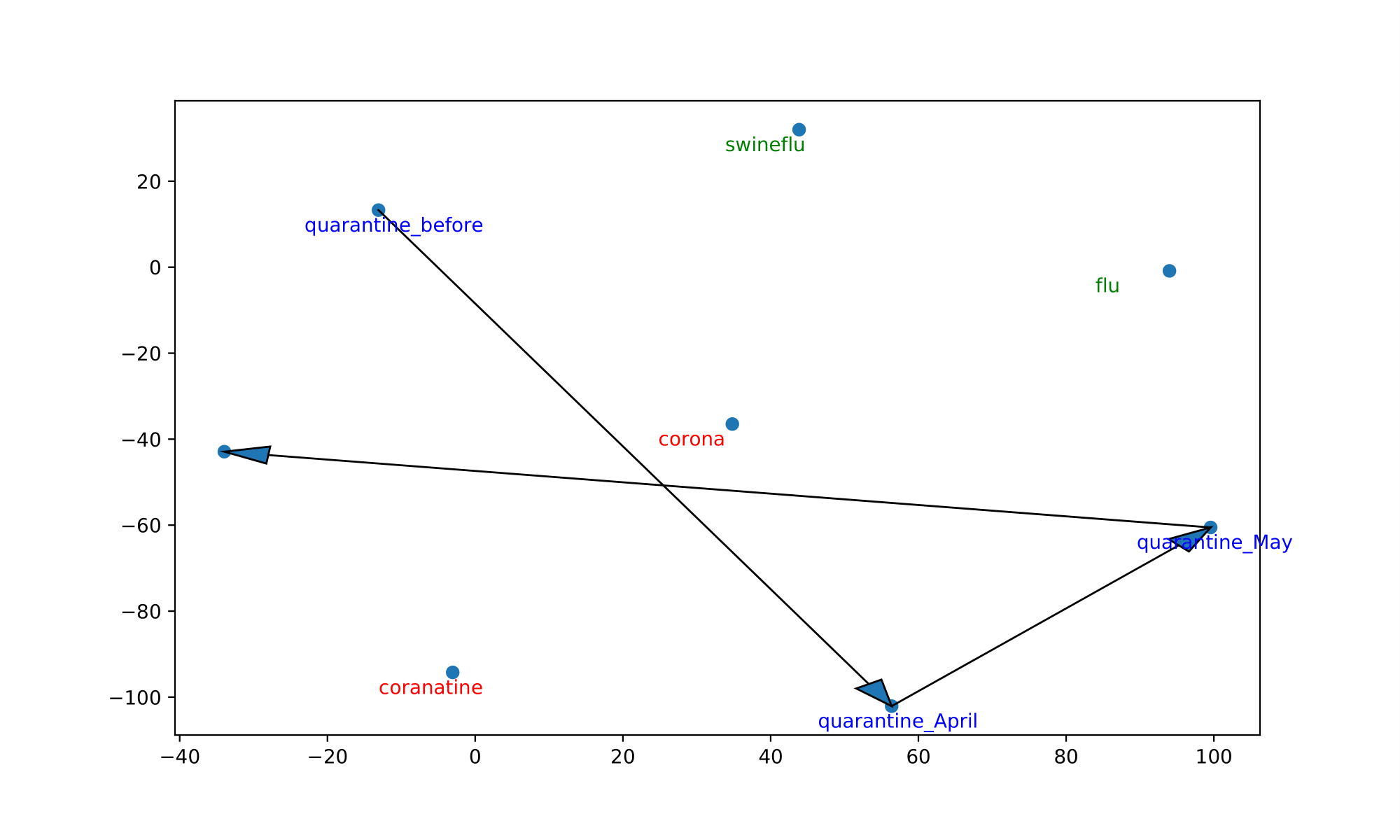
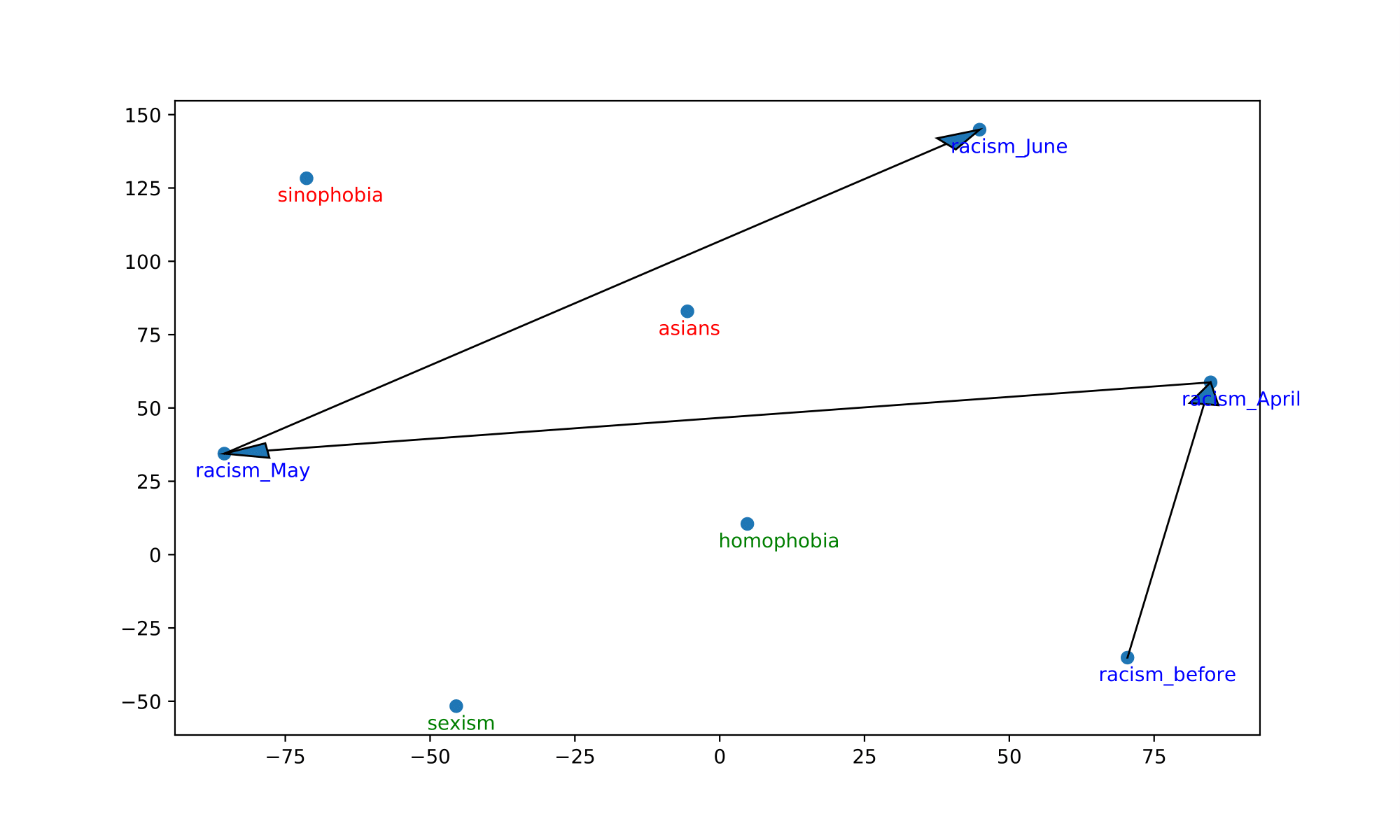
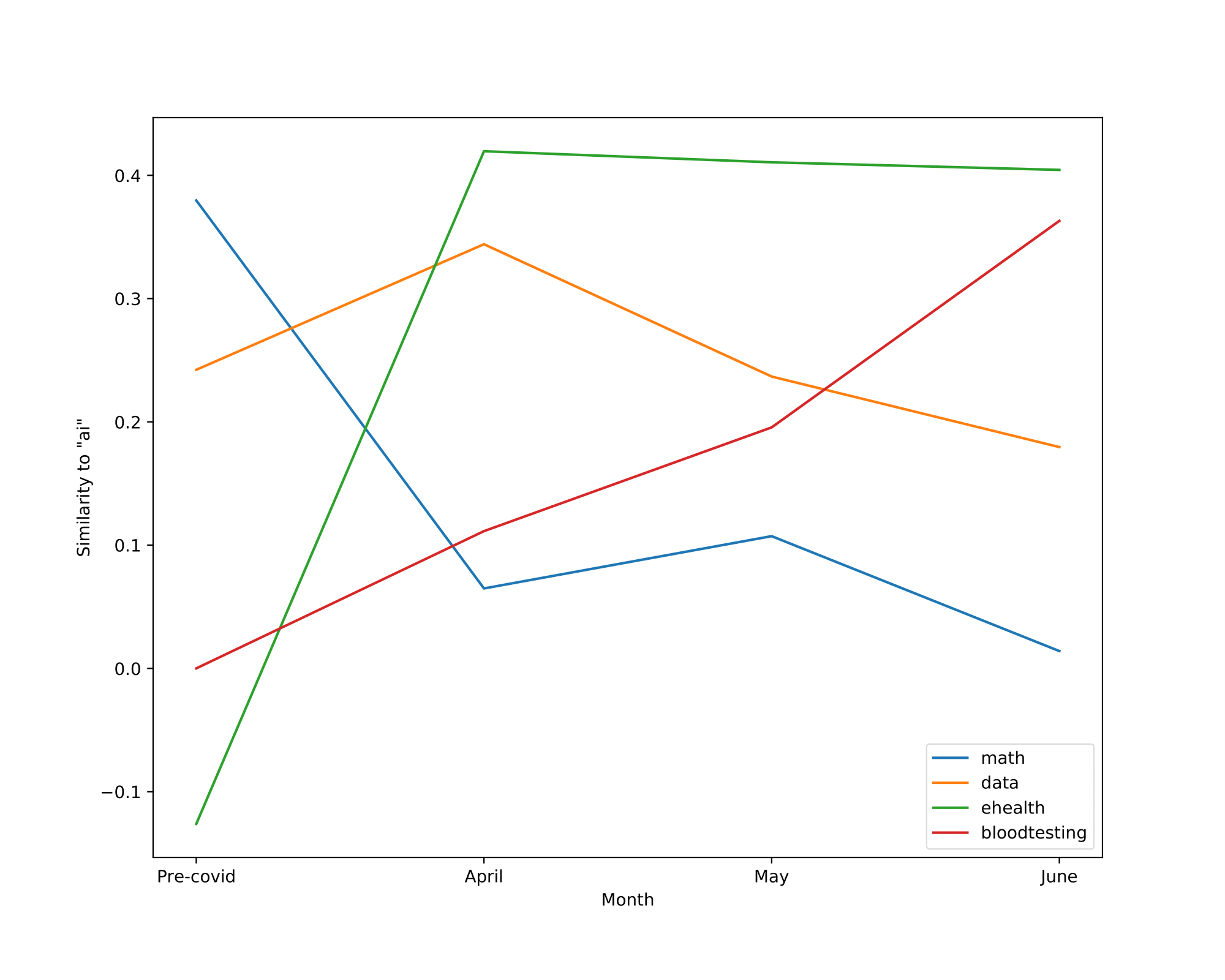
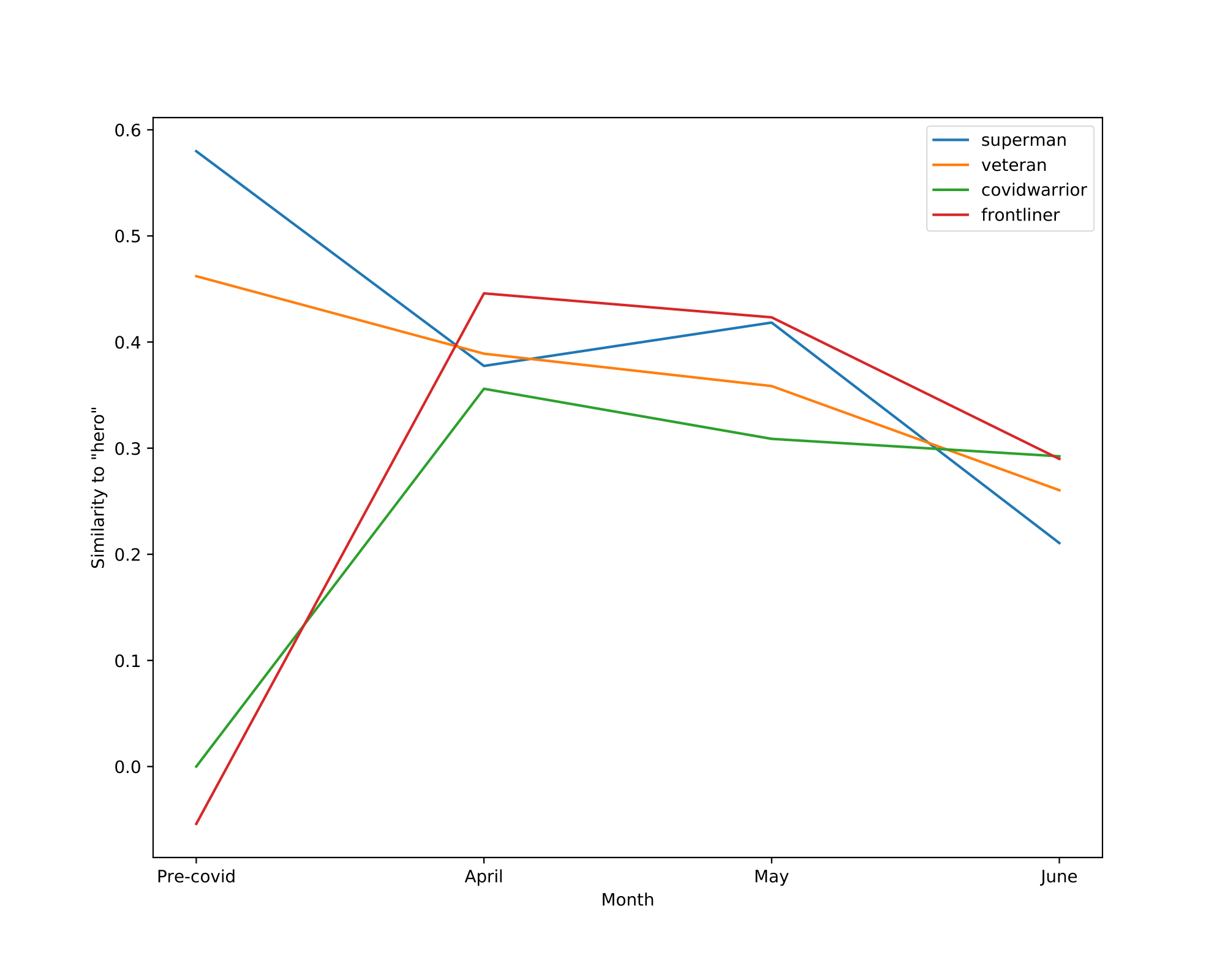
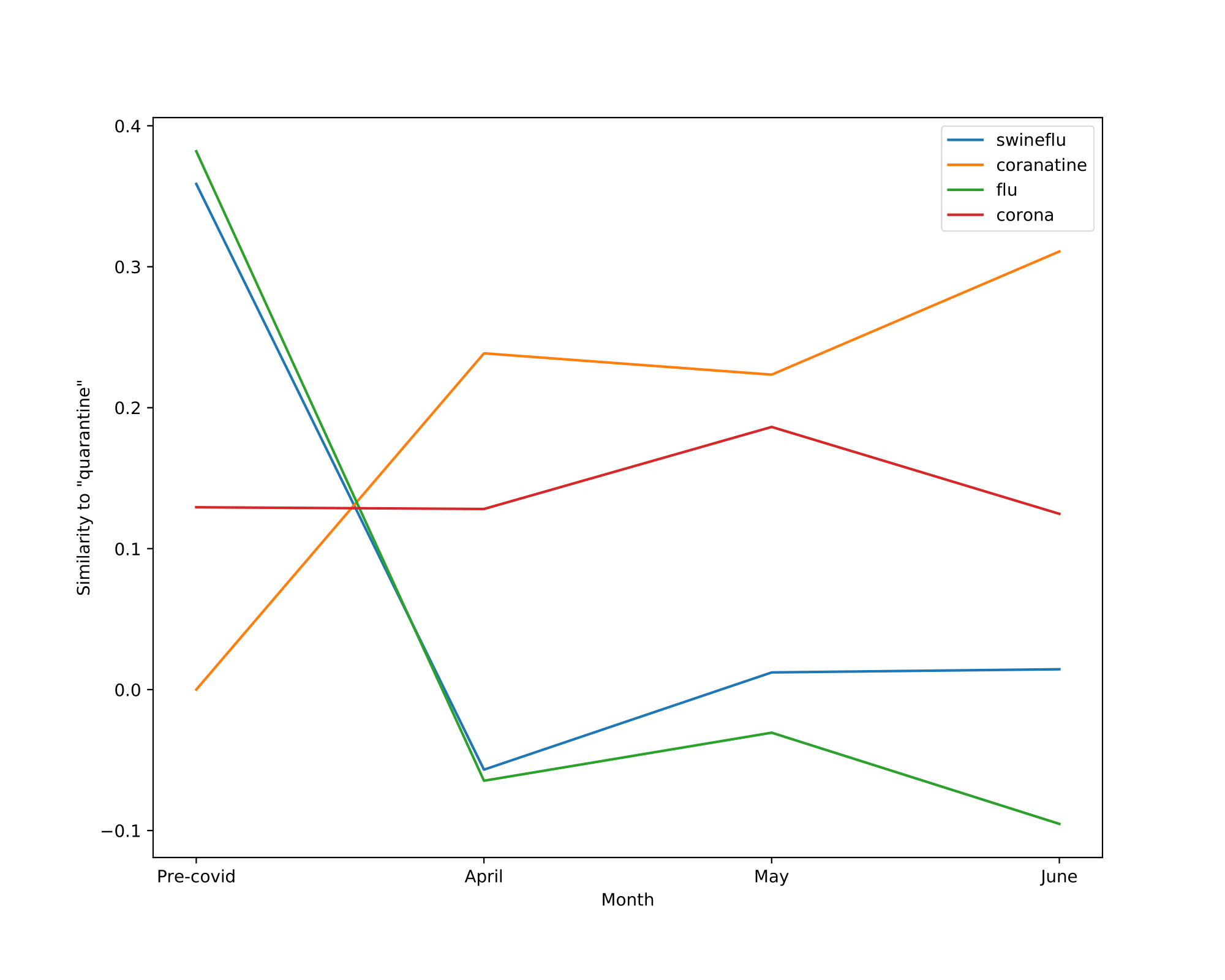
We also visualize the trajectory of words in the aligned embedding spaces which can help us understand the semantic shifts of words across contexts and over time. The following Table summarizes the semantic shifts of a set of example words. We pick four words of interest: racism, quarantine, hero and ai.
| Word | Moving away | Moving towards |
|---|---|---|
| racism | sexism, homophobia | asians, sinophobia |
| hero | veteran, superman | frontliner, covidwarrior |
| quarantine | swineflu, flu | coranatine, corona |
| ai | math, data | ehealth, bloodtesting |
Furthermore, the following Figure shows the trajectories of those words. We plot the 2-dimensional t-SNE projection of the target word’s embedding in each of the aligned models. We also plot some of the surrounding words of the target word in aligned models.
In all cases, the trajectory illustrations and similarity measures demonstrate that the words of interest have shifted significantly in meanings after the outbreak of COVID-19 and also show evolution over the three months. We see ”racism” move away from other general concepts of discrimination and end up close to words explicitly expressing hatred towards the Chinese/Asian community. This coincides with the worldwide anti-Asian phenomenon observable since the very beginning of the pandemic.
Finally, the Figure shown below illustrates the cosine similarity changes between the word of interest and surrounding words. Words that do not exist in the vocabulary of a certain model are assigned a similarity of 0 to all the other words within this given model.
 |
 |
 |
 |
In all cases, the trajectory illustrations and similarity measures demonstrate that the words of interest have shifted significantly in meanings after the outbreak of COVID-19 and also show evolution over the three months. We see ”racism” move away from other general concepts of discrimination and end up close to words explicitly expressing hatred towards the Chinese/Asian community. This coincides with the worldwide anti-Asian phenomenon observable since the very beginning of the pandemic.
Finally, the Figure shown below illustrates the cosine similarity changes between the word of interest and surrounding words. Words that do not exist in the vocabulary of a certain model are assigned a similarity of 0 to all the other words within this given model.
 |
 |
 |
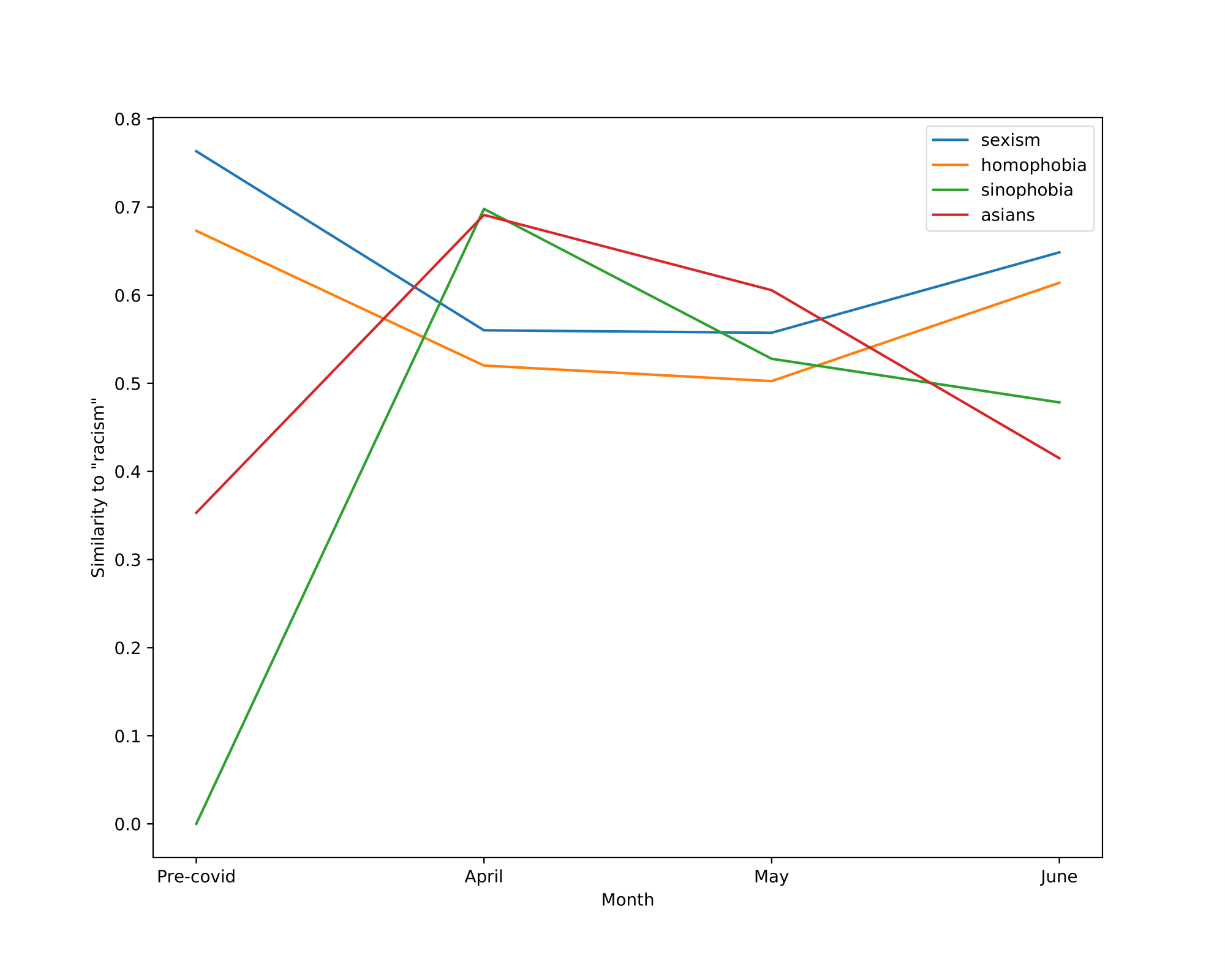 |
Interestingly, we can see that the similarity between racism and anti-Asian concepts spiked in April and started decreasing mildly in May and June, ndicating that people are slowly gaining back their rationality as the stage of COVID-19 progresses.