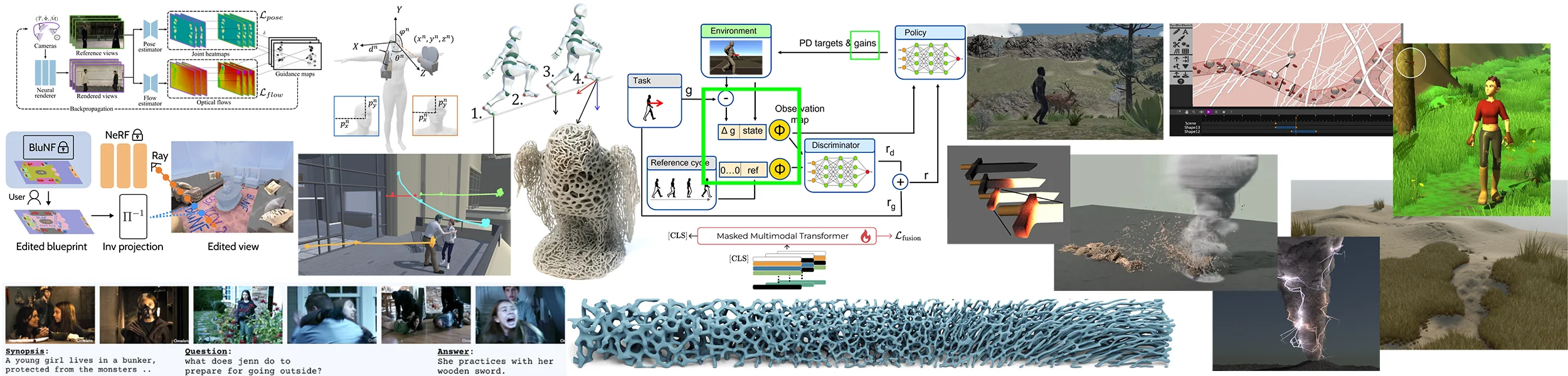
Our team develop new methods for the creation of Visual and Virtual Worlds with a specific focus on Storytelling for Animated Content. Our methods spans fully-automatic understanding of videos, up to the interactive creation of populated 3D virtual worlds. To this ends we are proposing methods improving the (i) Analysis of visual content, (ii) Shape and Motion representation, and (iii) the Creation of Visual Worlds.
We first propose fully Automatic AI-based Analysis of 2D Videos and 3D Animated Content that leverage Deep-Learning technics with a specific focus on time and multimodal input data. We are specifically developing methods for automatic human recognition, pose estimation, and behavior understanding. We also propose lightweight learning based on statistical approches to extract spatial relation between shapes from a single input.
Second, we develop Interactive Models to efficiently represent Shape and Motion. We are specialized in integrating spatio-temporal constraint into real-time reactive virtual models for game-like application using,either, explicit procedural models, or discovering them via Reinforcement-Learning. We also propose alternative, volume-based, representation for shapes modeling relying on implicit surface. These models are suited for complex shape synthesis or advanced interactive behaviors (precise collision, deformation). We finally develop layered and coupled models of different spatial/temporal nature adapted to simulate efficiently large and multi-scale natural scenes.
Third our models and analysis are aimed at the Creation and Authoring of Visual and Virtual Worlds. To this ends, we propose Expressive Creation Methodology, relying on Sketching or Sculpting Gestures, as well as Sound and Multimodal Systems. These steps are supported by the scene analysis allowing to provide suggestion system, up to helping the narrative design of the scene. We further propose transfert medodologies between geometry, animation, and style in complement to generative models in order to create lively and populated worlds with sufficient variety, or to explore the impact of parameters into a simulated world.
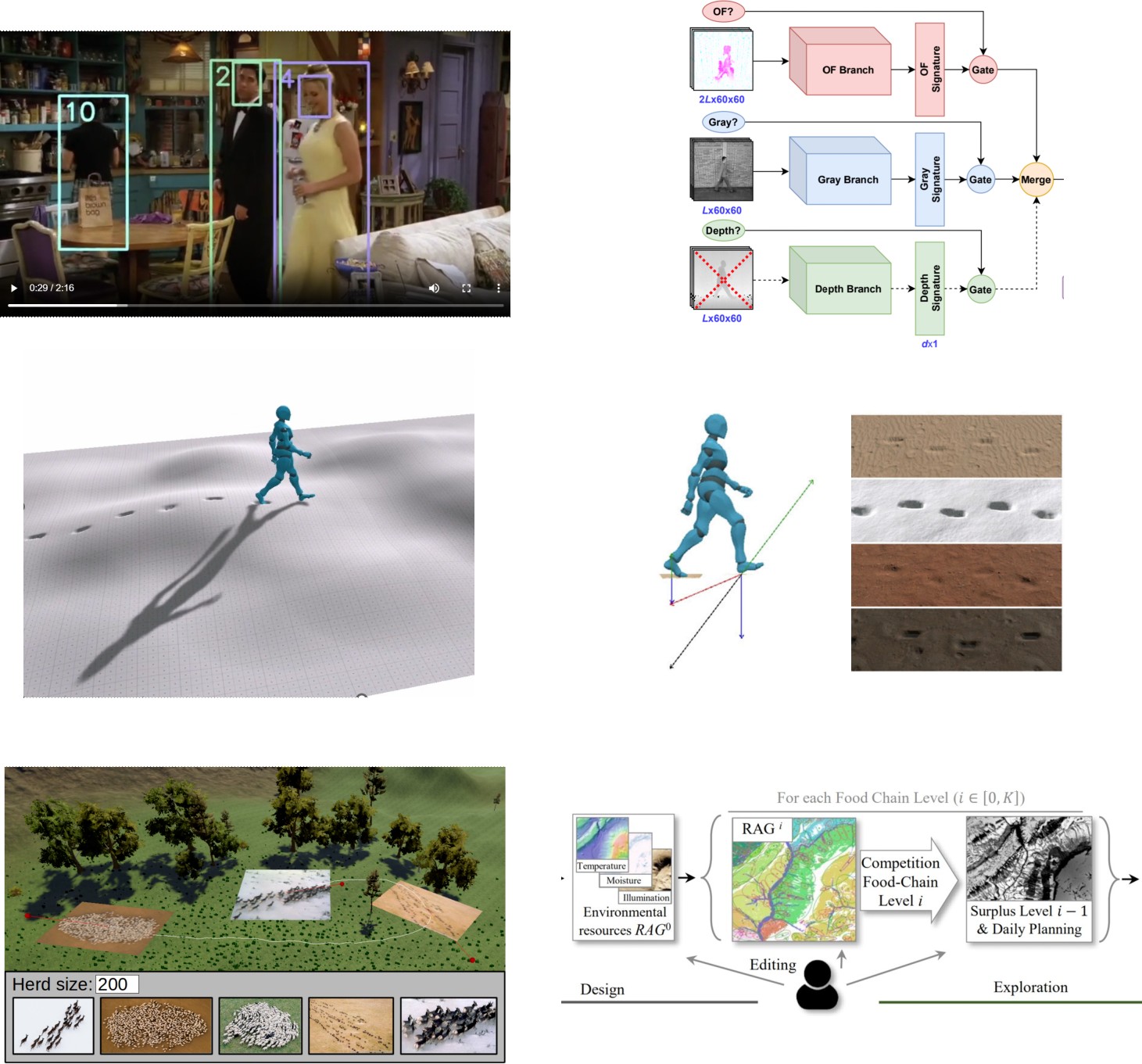
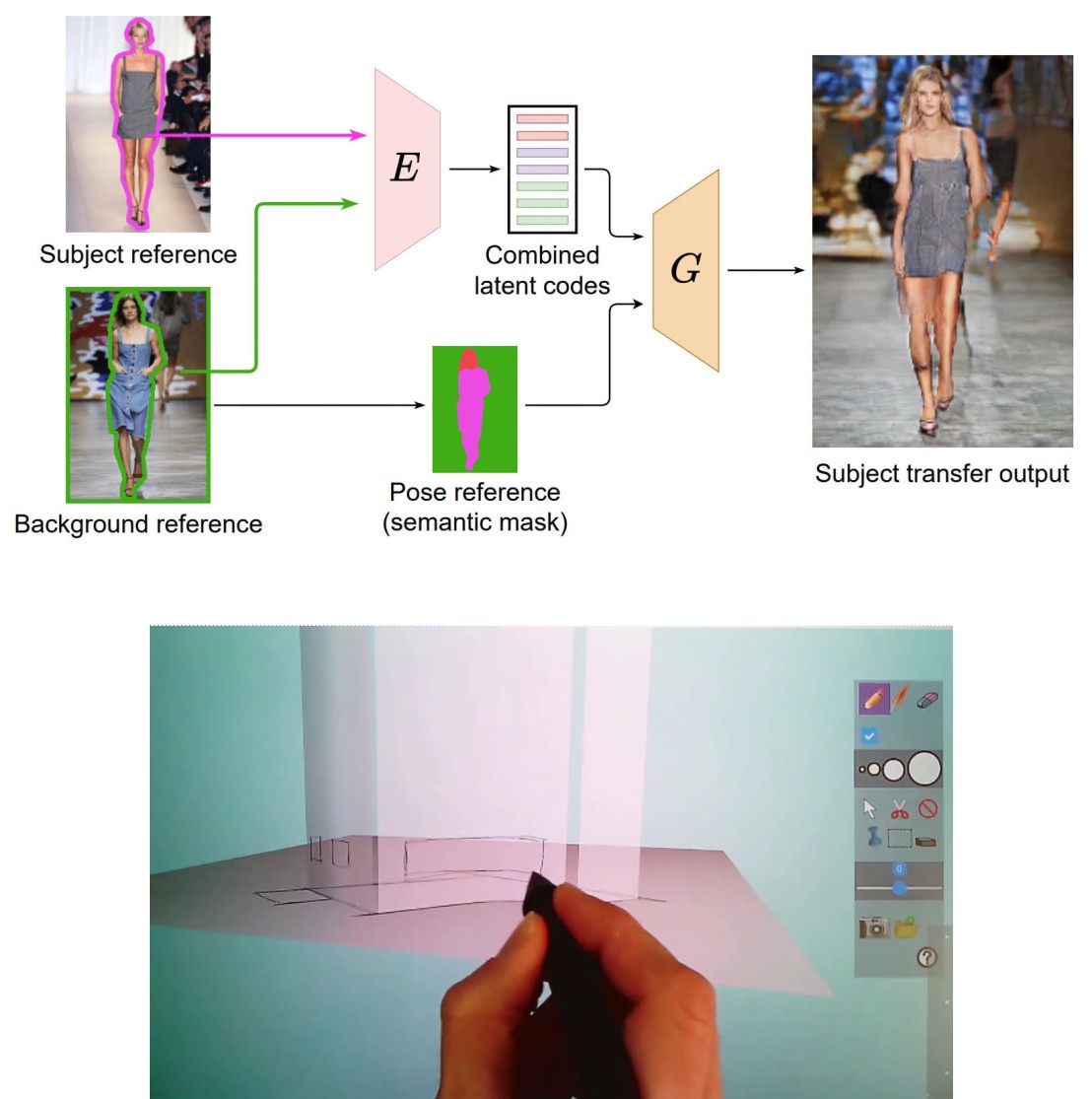
The specific aspect of our team-based methodology is propose a global Visual Computing approach coupling Automatic Vision and Interactive Graphics methodologies. This allows to tackle complex open scientific problems mixing the analysis of 2D and the synthesis of 3D content. For instance, we develop generative-based approaches ranging from automatic-learning fom data (GAN, diffusion, etc), reinforcement-learning, as well as alternative lightweight and efficient model relying on a-priori knowledge and user-centric design.
We are researchers with mixed expertises and backgrounds in Computer Graphics and Computer Vision. We jointly develop AI-based approaches and efficient representation to improve 2D video analysis and 3D animated virtual world generation.