The CPU (Central Processing Unit) of a computer is where all the
logical and arithmetic tests, loops and decisions take place, and
where control commands and data exchanges are issued to devices such
as memory, disk, screen, etc. The behaviour of the CPU is determined
by its state, which is described by the content of all its registers
and internal memory caches. Letting 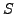 be the set of possible CPU
states, the CPU acts like a deterministic function
be the set of possible CPU
states, the CPU acts like a deterministic function 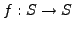 . According to this model, to each state
. According to this model, to each state 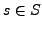 there corresponds
a next state
there corresponds
a next state 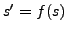 . The rate at which the CPU changes state is
governed by the system clock (usual rates are between 1 and 3
GHz). Thus, around every billionth of a second, the CPU changes its
state.
. The rate at which the CPU changes state is
governed by the system clock (usual rates are between 1 and 3
GHz). Thus, around every billionth of a second, the CPU changes its
state.
The form of the function 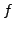 obviously depends on the CPU make and
model. CPUs usually contain some extremely fast but very small memory
chunks called ``registers'' which are specifically designed to store
either values or memory addresses. The state of the CPU at each clock
tick is then determined by the values contained in each of its
registers. The CPU is designed in such a way that at each clock tick
the memory address contained in a certain register will automatically
be incremented, and the value contained at the new address is read and
interpreted as a ``machine code instruction''. This allows us to
interpret the function
in a different way: we can consider the
next state
obviously depends on the CPU make and
model. CPUs usually contain some extremely fast but very small memory
chunks called ``registers'' which are specifically designed to store
either values or memory addresses. The state of the CPU at each clock
tick is then determined by the values contained in each of its
registers. The CPU is designed in such a way that at each clock tick
the memory address contained in a certain register will automatically
be incremented, and the value contained at the new address is read and
interpreted as a ``machine code instruction''. This allows us to
interpret the function
in a different way: we can consider the
next state 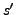 of the CPU as given by a function
of the CPU as given by a function
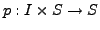 with
with 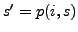 , where
, where 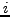 is a machine code instruction in the set
is a machine code instruction in the set
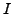 of all possible CPU instructions. Although each basic instruction
in
is rather simple, this interpretation of
makes it possible
to group several simple instructions into more complex
ones1. As some of the instructions
concern logical tests and loops, it becomes apparent that the full
semantics of any modern computer language (including C++) can indeed
be exploited by a CPU after a suitable transformation of the complex,
high-level language into the simple machine code instruction set
.
of all possible CPU instructions. Although each basic instruction
in
is rather simple, this interpretation of
makes it possible
to group several simple instructions into more complex
ones1. As some of the instructions
concern logical tests and loops, it becomes apparent that the full
semantics of any modern computer language (including C++) can indeed
be exploited by a CPU after a suitable transformation of the complex,
high-level language into the simple machine code instruction set
.
Loosely speaking, the set
can be partitioned in the following
instruction categories.
- Input: transfer data from external device to processor
- Output: transfer data from processor to external device
- Storage: transfer data from processor to memory
- Retrieval: transfer data from memory to processor
- AL operation: perform arithmetic/logical operation on data
- Test: verify condition on data and act accordingly
- Loop: repeat a sequence of operations
In practice, these instructions are encoded in machine language,
i.e. sequences of bits. The length of each instruction depends on the
width of the CPU registers. The width of each register is measured in
terms of the amount of BInary digiTs  (bits) it can
contain. Traditionally, on Intel 16-bit architectures (32- and 64- bit
architectures are evolutions thereof, and each new version is
guaranteed to retain backward compatibility) there are four
general-purpose registers: AX (accumulator), BX (base), CX (counter),
DX (data); four pointer registers: SI (source index), DI (destination
index), BP (base pointer), SP (stack pointer); four segment registers:
CS (code segment), DS (data segment), ES (extra segment), SS (stack
segment); and finally, one instruction pointer IP. The machine code
instruction
loaded at each clock tick to compute
is
the value found at the address CS:IP. More information can be found
at http://www.ee.hacettepe.edu.tr/~alkar/ELE414/ and
http://ourworld.compuserve.com/homepages/r_harvey/doc_cpu.htm.
(bits) it can
contain. Traditionally, on Intel 16-bit architectures (32- and 64- bit
architectures are evolutions thereof, and each new version is
guaranteed to retain backward compatibility) there are four
general-purpose registers: AX (accumulator), BX (base), CX (counter),
DX (data); four pointer registers: SI (source index), DI (destination
index), BP (base pointer), SP (stack pointer); four segment registers:
CS (code segment), DS (data segment), ES (extra segment), SS (stack
segment); and finally, one instruction pointer IP. The machine code
instruction
loaded at each clock tick to compute
is
the value found at the address CS:IP. More information can be found
at http://www.ee.hacettepe.edu.tr/~alkar/ELE414/ and
http://ourworld.compuserve.com/homepages/r_harvey/doc_cpu.htm.
Consider now the following (informal) definitions:
- Program: set of instructions that can be interpreted
by a computer
- Instructions: well-formed sequences of characters (syntax)
- Interpretation: sequence of operations performed by
the computer hardware (semantics)
- Programming language: set of rules used to form
valid instructions
- Algorithm: a program which terminates (though
sometimes find ``non-terminating algorithm'' with abuse of
notation)
The well-formedness of the sequence of characters in each instruction
corresponds to the C++ syntax which is one of the subjects of these
notes, and will therefore be explained in more detail later. The same
holds for the semantics of each C++ program.
Leo Liberti
2008-01-12