
Visual representation is a universal medium for humans to express ideas and communicate in conveying both spatial and temporal information when animated. Visual representations are in particular the main support for the understanding of our environment as humans, allowing us to shape in our mind virtual, realistic or imaginary worlds. These worlds, ranging from reality reproduction to fully abstract, are open to endless human creativity but are, conversely, hard to formalize as computational models, and therefore cannot be easily represented back visually.
We believe that coupling vision-based analysis with efficient virtual models via expressive human interaction is a powerful computational way to synthesize and control such virtual worlds, allowing them to be shared with their creator as well as others, thus leveraging human creativity and understanding for various application domains. For instance in digital fabrication, fashion designers may want to interactively refine their new garments while preserving the silhouettes and motions from other collections; Natural scientists may want to express their mental image of a complex phenomenon based on a few visual observations that need to be refined; or game designers may want to reproduce plausible crowds from videos footage while sketching new events that need to be simulated over the visual scene. Our focus is to propose algorithms and methodologies bringing to amateur or professional users the possibility to seamlessly create, explore, and interact with their own virtual worlds.
In addition, and thanks to recent advances of deep learning coupled with the availability of big data, automatic understanding of the semantic content of videos -- either real (such as home clips, feature films) or virtual, synthesized ones -- are able to infer high-level past and future semantic concepts. We therefore also aim at transferring these semantic concepts to other domains and have the ability to automatically explain their decisions or to recognise their limitations.

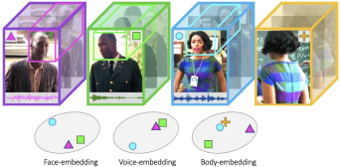 We propose in this axis the development of novel methods based on both light and/or deep learning for the analysis and understanding of visual inputs. We aim at tackling first the improvement of fully automatic machine learning approaches for image and video data understanding [Kalogeiton17, Marin-Jimenez20, Liu20]. In particular, while the traditional machine learning paradigm depends on the annotated data with separated test phases, we plan to develop methods that exploit domain adaptation, self-supervised and unsupervised learning, thus avoiding the heavy and tedious needs for annotations. We further wish to extend our deep learning methods to multimodal understanding in order to take advantage of multiple inputs such as voice and text to be coupled with visual inputs [Brown21]. On the other side, we also plan to develop lightweight learning approaches applied to vectorial data and in particular to analyse spatial-representation [Mercier18, Ecormier19] that can typically be used when synthesizing natural sciences visual representation from a few drawings or animation. An example of such analysis is the extension of pair correlation functions toward geometrical shapes in order to be used in shape assembly synthesis based on very few examples.
We propose in this axis the development of novel methods based on both light and/or deep learning for the analysis and understanding of visual inputs. We aim at tackling first the improvement of fully automatic machine learning approaches for image and video data understanding [Kalogeiton17, Marin-Jimenez20, Liu20]. In particular, while the traditional machine learning paradigm depends on the annotated data with separated test phases, we plan to develop methods that exploit domain adaptation, self-supervised and unsupervised learning, thus avoiding the heavy and tedious needs for annotations. We further wish to extend our deep learning methods to multimodal understanding in order to take advantage of multiple inputs such as voice and text to be coupled with visual inputs [Brown21]. On the other side, we also plan to develop lightweight learning approaches applied to vectorial data and in particular to analyse spatial-representation [Mercier18, Ecormier19] that can typically be used when synthesizing natural sciences visual representation from a few drawings or animation. An example of such analysis is the extension of pair correlation functions toward geometrical shapes in order to be used in shape assembly synthesis based on very few examples.

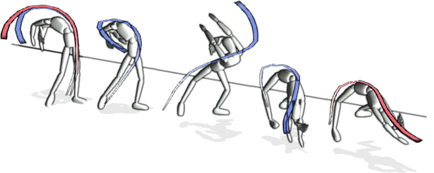
In this axis, we focus on the development of new virtual models adapted to user interaction, sharing the constraint of proposing efficient and controllable ways to represent plausible phenomena. We first propose new fundamental representations such as the extension of implicit surfaces, or more generally field based representations, to handle challenging operations on 3D geometry such as robust contact handling between detailed surfaces [Buffet19], arbitrary modification of topology, mutual influence between surfaces, and bio-inspired generation. Second, we aim at efficiently integrating geometrical [Fondevilla17, Bartoz18] as well as spatio-temporal constraints [Manteau16] on arbitrary shapes. For instance, we may need to constrain locally the volume of a deforming blood-cell that propagates in virtual capillaries, or to propose real-time cartoon inspired deformers that adapt to the velocity and acceleration of a character for entertainment applications [Rohmer21]. Third, we aim at proposing visual simulation, i.e. plausible and real-time simulation without aiming at predictive numerical results. To this end, we rely mostly on the methodology of layered-models, where a complex phenomenon is decomposed in a subset of simple, efficient, and dedicated sub-models, that are possibly coupled together [Cordonnier18, Vimont20, Paliard21]. Finally we also tackle behavioral simulation of virtual character, typically using reinforcement learning, that could be ultimately coupled with complex visual simulations.
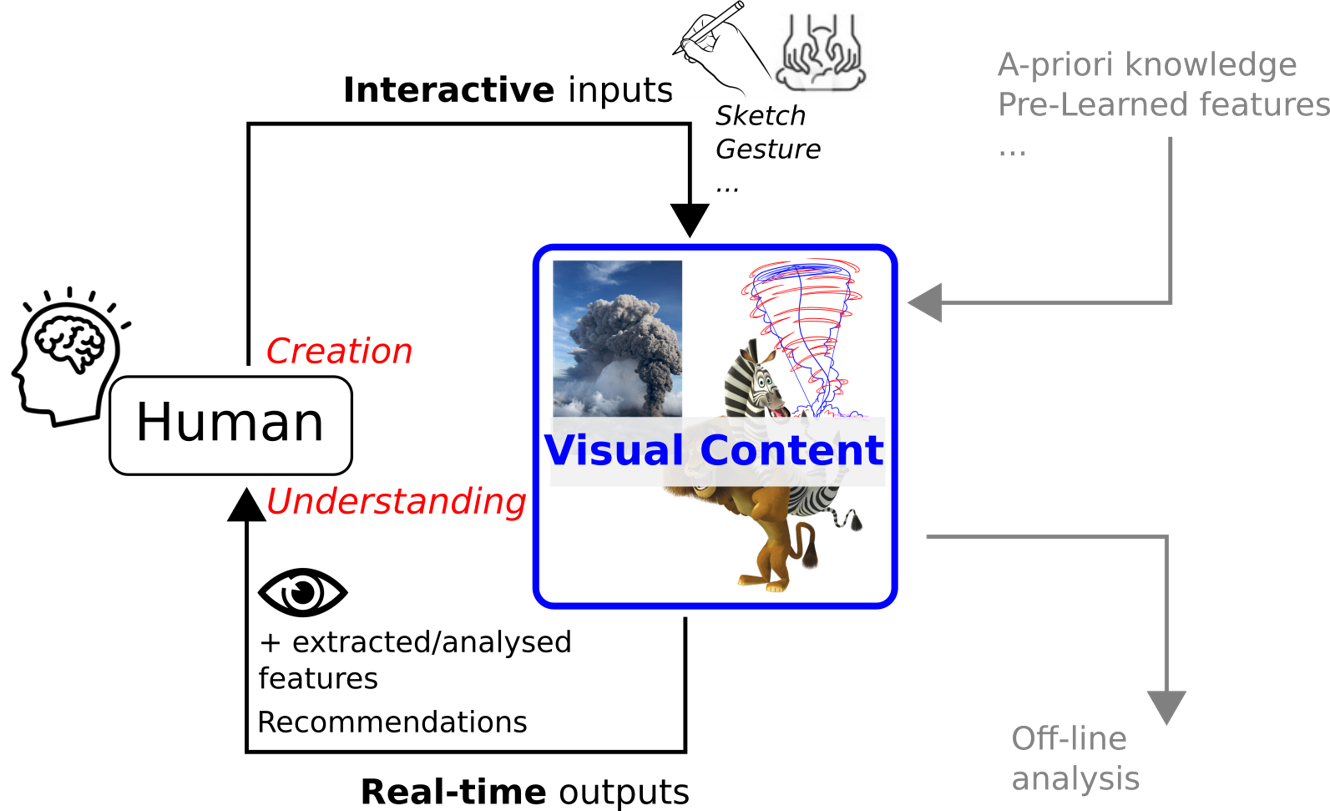
This last axis aims at developing high level models for the generation and/or human-centric control of realistic or imaginary worlds. First we propose expressive creation methodologies typically using sketching [Olivier19, Entem19, Parakkat21], sculpting [Cordonnier2018_B] or mimic gestures[Garcia19] as input, to represent salient features of a model, that are interpreted as high level constraints for shape or motion. We further wish to extend our methodology to multimodal-based creation systems, in mixing sketches as well as sound or VR inputs to increase the degree of freedom and expressiveness during the creation process [Nivaggioli19]. In addition, we also consider the use of high level a-priori or learned knowledge for the creation of these visual worlds, typically to instantiate a plausible 3D representation from a few sets of parameters or examples [Ecormier19_B,Ecormier21]. In the context of more realistic representation, we aim at proposing cinematographic and narrative constraints, as well as an automatic suggestion system. While virtual videos require combining different shots taken from different cameras and viewpoints, we alleviate this in developing deep learning techniques that enable fast editing of visual data by exploiting real-life video data (including home video clips, tv shows, and movies), e.g., by learning mappings between input video contents and styles (e.g., viewpoints, motions, edits, or cutting rhythm). Moreover, due to the growing need of compelling narrative experiences in virtual worlds, we are interested in generating a collection of visual suggestions, for instance by integrating dedicated content creation tools, especially ones that ease the reproduction of visual conventions on 3D animated contents. Finally, we are also studying generation and style transfert - first in disentangling conditional Generative Adversarial Networks and in developing tools to generate realistic audio-visual data, including low-level analysis of multi-modal data, semantic person-centric approaches, and temporal aspects. And, in addressing multiple style transfer in videos by exploiting Variational Autoencoders, the temporal consistency of videos, and Visual Transformers.