Recherche

Sur un plan scientifique, mes principaux centres d'intérêts se situent à l'interface entre Informatique, Mathématiques et Biologie Moléculaire. La finalité de mes travaux est principalement la conception d'approches analytiques, d'algorithmes efficaces et d'outils finalisés en direction de la biologie des Acides RiboNucléiques (ARN).
Quelques unes des questions soulevées sont les suivantes :
- Comment prédire la structure de l'ARN en présence de pseudonoeuds ?
- Quelle est la prévalence des phénomènes cinétiques à l'oeuvre au cours du repliement de l'ARN ?
- Quelle relation entre la structure et l'évolution des ARN ?
En quoi l'évolution des séquences d'ARN nous renseigne-t-elle sur leur structure ? - En quoi la connaissance de la structure d'un ARN est susceptible d'aider à l'analyse des données expérimentales ?
À l'inverse, comment tirer parti de données experimentales gros grain pour prédire la structure secondaire d'un ARN ? - Comment concevoir une séquence d'ARN réalisant une fonction souhaitée in vivo ?
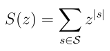
Certaines de ces questions ont trait à des propriétés universelles des biopolymères, et ne requièrent la prise en compte ni d'une séquence précise d'ARN, ni d'un modèle énergétique sophistiqué. En supposant qu'elles puissent être réexprimées à tel un niveau abstrait sans en sacrifier l'essence, j'utilise les outils issus de la combinatoire énumérative et de la combinatoire analytique pour obtenir des réponses quantitatives (asymptotiquement) exactes.
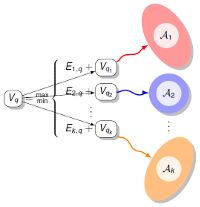
Des questions plus complexes exigent parfois une analyse spécifique de chaque séquence, tout en autorisant la mise en oeuvre d'algorithmes, souvent issus de la programmation dynamique, de complexité temps/mémoire polynomiales. Les concepts et principes sous-jacents à ces algorithmes sont alors parfois d'un niveau de généralité suffisant pour autoriser leur transposition à d'autres domaines. Par exemple, j'exporte en direction de la génomique comparative des méthodes ensemblistes introduites dans le contexte de la thermodynamique, entre autres afin de tester la robustesse des prédictions obtenues selon un principe de parcimonie.
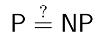
Il arrive cependant que les problèmes considérés soient d'une difficulté algorithmique démontrable au sens de la théorie de la complexité. Dans une tel cas, j'essaye d'établir l'origine de la difficulté du problème afin d'envisager des stratégies de contournement. Par exemple, on pourra envisager la conception d'un algorithme de complexité paramétrée, ou encore une simplification du modèle réalisant un compromis acceptable entre expressivité and calculabilité en temps raisonnable.
Enfin, dans les cas extrêmes où le problème est difficile à appréhender, ou encore, de façon croissante, comme une approche préliminaire pour tester des hypothèses et me familiariser avec un problème, j'adopte une approche probabiliste, basée sur la génération aléatoire contrainte dans des distributions adéquates, telle la distribution uniforme, ou encore la distribution de Boltzmann.