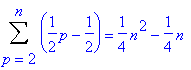- À quoi sert Access ? enregistrements
- Les objetsenregistrements champs
access vs excel
- Les tables
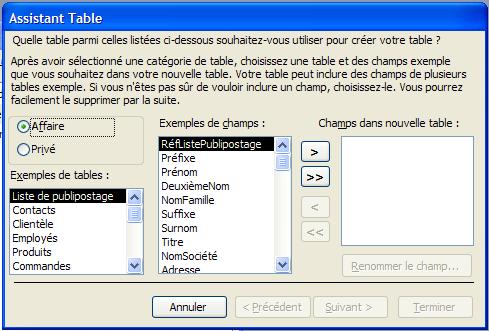
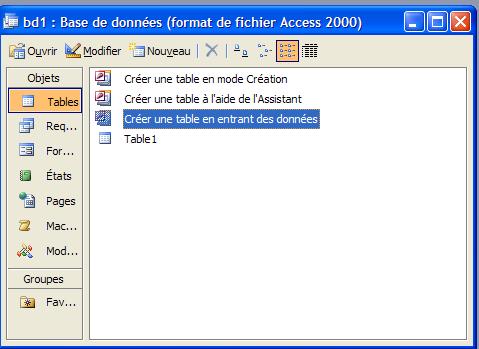
- CréationIl y a plusieurs possibilités pour créer une table:
- Type des données
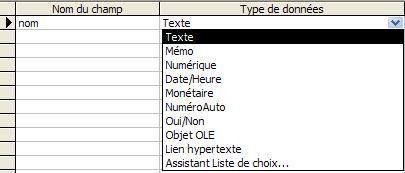
- Texte
Utilisez ce type de champ pour du texte ou des combinaisons de texte et de chiffres, telles que des adresses, ou des nombres qui ne nécessitent aucun calcul, tels que des numéros de téléphone, des numéros de pièce ou des codes postaux.
Stocke jusqu'à 255 caractères. La propriété FieldSize contrôle le nombre maximal de caractères qui peuvent être saisis:
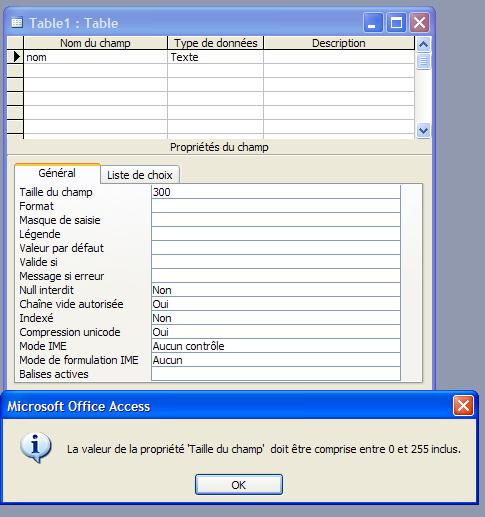
-
Mémo
Utilisez ce type de champ pour de longues suites de caractères alphanumériques, telles que des notes ou des descriptions. Stocke jusqu'à 65 536 caractères. - Numérique
Utilisez ce type de champ pour les données numériques à inclure dans des calculs mathématiques, à l'exception des calculs monétaires (pour lesquels vous devez utiliser le type Monétaire).
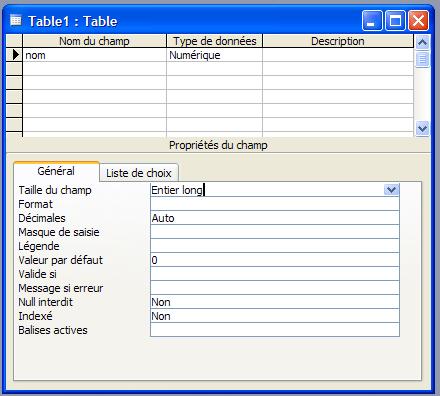
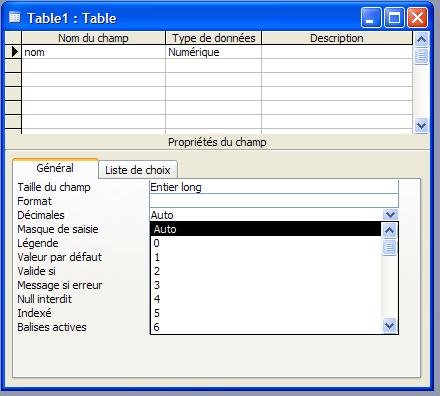
Stocke 1, 2, 4 ou 8 octets ; stocke 16 octets pour le N° de réplication (GUID). La propriété FieldSize définit le type Numérique spécifique.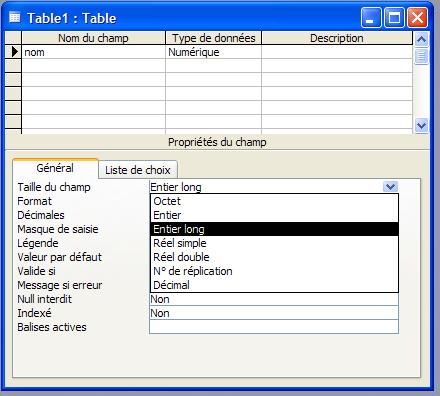
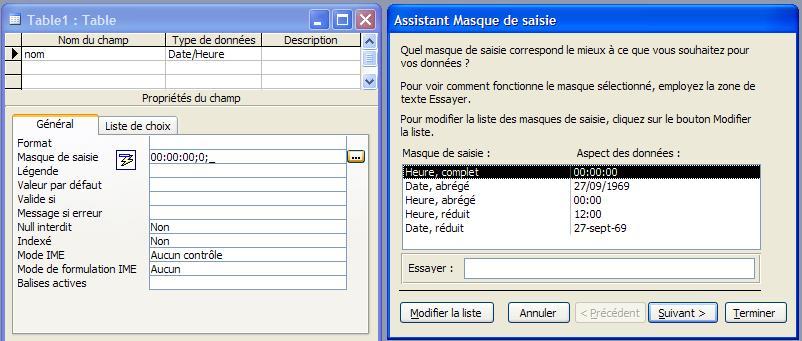
- Date/Heure
Utilisez ce champ pour les dates et les heures. Stocke 8 octets.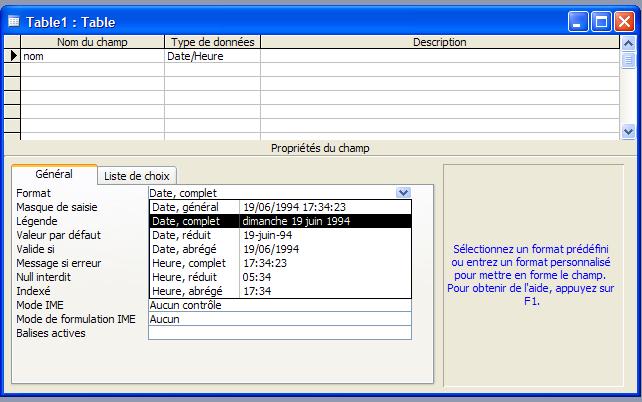
- Monétaire
Utilisez ce type de champ pour les valeurs de type monétaire et pour empêcher l'arrondissement au chiffre supérieur lors des calculs. Stocke 8 octets.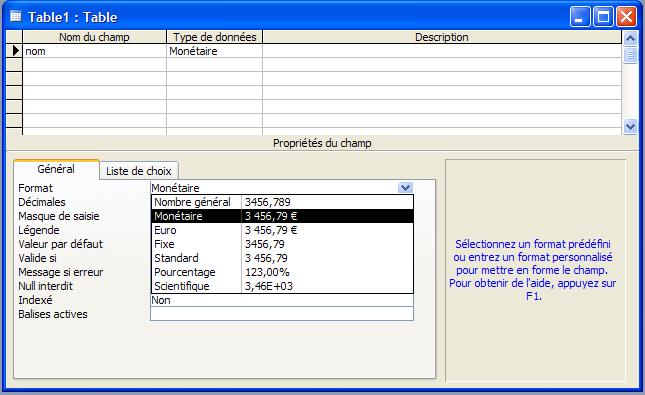
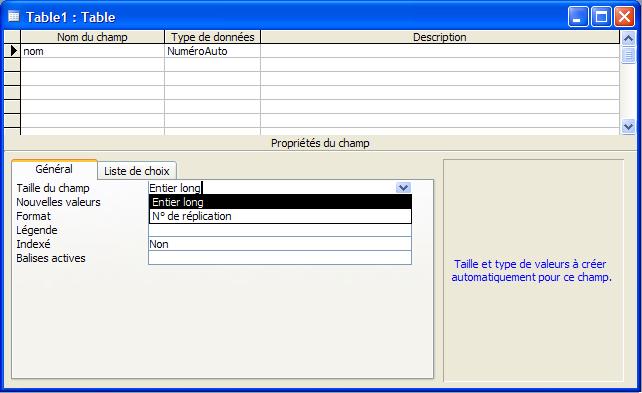
- NuméroAuto
Utilisez ce type de champ pour les numéros séquentiels (augmentant d'une unité) ou aléatoires qui sont insérés automatiquement lors de l'ajout d'un enregistrement. Stocke 4 octets ; stocke 16 octets pour le N° de réplication (GUID).
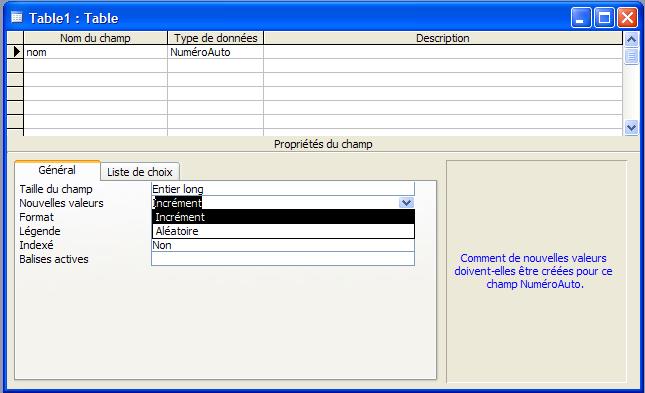
- Oui/Non
Utilisez ce type de champ pour les données qui ne peuvent être que d'une de deux valeurs possibles, notamment Oui/Non, Vrai/Faux ou Actif/Inactif.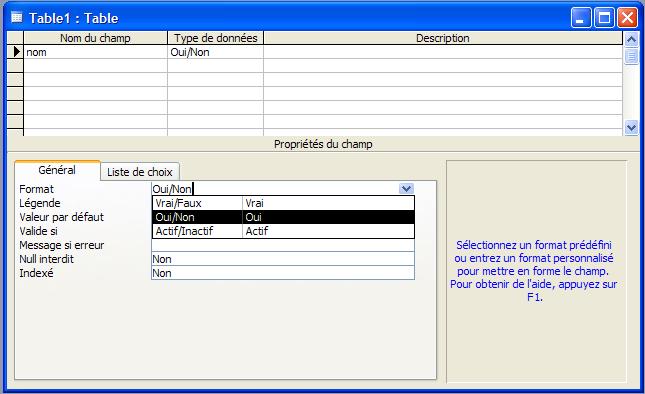
Les valeurs Null ne sont pas autorisées. Stocke 1 octet. -
Mémo
- Objet OLE
Utilisez ce type de champ pour les objets OLE (notamment des documents Microsoft Word, des feuilles de calcul Microsoft Excel, des images, des sons ou d'autres données binaires), créés dans d'autres programmes à l'aide de la technologie OLE. Stocke jusqu'à 1 giga-octet (limité par l'espace disque disponible). - Lien hypertexte
Utilisez ce type de champ pour les liens hypertexte. Stocke jusqu'à 64 000 caractères. - Assistant Liste de
choix
Utilisez cet Assistant pour créer un champ qui permet de choisir une valeur dans une autre table ou une liste de valeurs présentées dans une zone de liste déroulante. Le choix de cette option dans la liste des types de données démarre un Assistant qui exécute automatiquement cette définition.
Vous devez choisir le type de champ en fonction de ce que vous souhaitez faire. Voici quelques informations:
- Vous pouvez additionner des valeurs dans des champs de type Numérique ou Monétaire, mais pas dans des champs de type Texte ou Liaison OLE
- Vous ne pouvez pas effectuer un regroupement sur un champ de type Liaison OLE
- Dans un champ Texte, les nombres sont triés comme des chaînes de caractères (1, 10, 100, 2, 20, 200, etc.), et non comme des valeurs numériques. Si vous souhaitez effectuer un tri sur des nombres, utilisez un champ de type Numérique ou Monétaire. Il en est de même pour les dates ; si vous devez effectuer un tri sur des dates, définissez ce champ comme un champ de type Date/Heure et non comme un champ de type Texte.
- Vous pouvez trier ou regrouper des données dans un champ de type Texte ou Mémo. Toutefois, Microsoft Access utilise uniquement les 255 premiers caractères lorsque vous triez ou regroupez des données dans un champ de type Mémo.
- Utilisez un champ de type Numérique lorsque vous souhaitez stocker des
nombres sur lesquels vous effectuerez des calculs, sauf s'il s'agit de
valeurs en devises ou de nombres nécessitant un calcul très précis. Le
type de nombre et la taille des valeurs numériques que vous pouvez stocker
dans un champ de ce type sont définis par la propriété
TailleChamp (FieldSize). Par exemple, l'option Octet ne permet que de
stocker des nombres entiers (les décimales ne sont pas autorisées) compris
entre 0 et 255 et n'occupe qu'un octet sur le disque dur.
Utilisez un champ de type Monétaire lorsque vous ne voulez pas arrondir les calculs. Dans un champ de ce type, vous pouvez avoir des nombres de 15 chiffres plus quatre chiffres après la virgule. Un champ de type Monétaire occupe 8 octets sur le disque dur.
- Texte
- Clé primaireIl est possible de trouver et
de réunir rapidement des informations stockées dans des tables séparées en
utilisant des requêtes, des formulaires, et des états. A cette fin, chaque
table doit inclure un champ ou un ensemble de champs qui identifie, de
manière unique, chaque enregistrement stocké dans la table. Cette
information est appelée la clé primaire de la table. Une fois que vous avez
désigné une clé primaire pour une table, Access empêchera que des doublons
ou des valeurs
Null ne soient entrées dans les champs Clé primaire
Il existe trois types de clés primaires:- Les clés primaires NuméroAuto:
un champ NuméroAuto peut être défini pour entrer automatiquement un numéro séquentiel lors de l'ajout de chaque enregistrement à la table. C'est la manière la plus simple de créer une clé primaire. Si vous ne définissez pas de clé primaire avant d'enregistrer une nouvelle table, Microsoft Access vous propose d'en créer une à votre place. Si vous répondez Oui, Microsoft Access crée une clé primaire Numérotation automatique. - Les clés primaires à champ simple
Si un de vos champs contient des valeurs uniques comme des numéros d'identification ou des numéros de pièces, vous pouvez le désigner comme clé primaire. Vous pouvez spécifier une clé primaire pour un champ qui contient déjà des données tellement longues que ce champ ne contient pas de valeurs en doublons ou Null. - Les clés primaires à champs multiples
Dans les cas où vous ne pouvez pas garantir le caractère unique d'un seul champ, vous pouvez désigner deux ou plusieurs champs comme clé primaire.
Si vous n'êtes pas sûr d'utiliser une bonne combinaison de champs pour une clé primaire composée, il est préférable d'ajouter un champ Numérotation automatique et de le désigner comme clé primaire. Par exemple, la combinaison des champs Prénom et Nom n'est pas à conseiller, puisque vous pouvez rencontrer des doublons dans la combinaison de ces deux champs.
Dans une clé primaire composée, l'ordre des champs peut avoir de l'importance pour vous. Les champs dans une clé primaire composée sont triés en fonction de leur ordre dans la table en Mode création.
- Les clés primaires NuméroAuto:
- RelationsAprès avoir défini plusieurs
tables pour les différents sujets traités dans votre base de données, il
vous faut indiquer comment rassembler à nouveau ces informations. La
première étape consiste à définir des relations entre vos différentes
tables. Après quoi vous pouvez créer des requêtes, des formulaires et des
états pour afficher des données provenant de plusieurs tables différentes.
Une relation a pour principe la correspondance des données des champs clés
de deux tables — ces champs ont généralement le même nom dans les deux
tables. Dans la plupart des cas, ces champs sont la clé primaire de l'une
des tables, qui fournit un identificateur unique pour chaque enregistrement,
et une clé étrangère dans l'autre table.
Il existe plusieurs types de relations- un à plusieurs:
La relation un-à-plusieurs est la plus courante. Dans ce type de relation, un enregistrement de la table A peut être mis en correspondance avec plusieurs enregistrements de la table B, alors qu'à chaque enregistrement de la table B ne correspond qu'un enregistrement de la table A. - un à un:
Dans une relation un-à-un, chaque enregistrement de la table A ne peut correspondre qu'à un enregistrement de la table B, et inversement, chaque enregistrement de la table B ne peut correspondre qu'à un enregistrement de la table A. Ce type de relation est peu courant, car la plupart des informations qui seraient associées de la sorte font normalement partie d'une même table. Vous pouvez utiliser une relation un-à-un pour diviser une table qui a de nombreux champs, pour isoler une partie d'une table pour des raisons de sécurité, ou pour stocker des informations ne s'appliquant qu'à un sous-ensemble de la table principale. - plusieurs à plusieurs
Dans une relation plusieurs-à-plusieurs, un enregistrement de la table A peut être mis en correspondance avec plusieurs enregistrements de la table B, et inversement, un enregistrement de la table B peut être mis en correspondance avec plusieurs enregistrements de la table A. Ce type de relation n'est possible qu'après définition d'une troisième table (appelée table de jonction), dont la clé primaire est constituée de deux champs — les clés étrangères des tables A et B. Une relation plusieurs-à-plusieurs n'est en fait rien d'autre que deux relations un-à-plusieurs avec une troisième table.
Le type de relation créé dépend de la manière dont les champs liés sont définis :
- Une relation un-à-plusieurs est créée si un seul des champs liés est une clé primaire ou a un index unique.
- Une relation un-à-un est créée si les deux champs liés sont des clés primaires ou ont des index uniques.
- Une relation plusieurs-à-plusieurs est en fait composée de deux relations un-à-plusieurs, avec une troisième table dont la clé primaire consiste en deux champs, qui sont les clés étrangères des deux autres tables.
L'intégrité référentielle est un système de règles que utiliser pour garantir que les relations entre les enregistrements dans les tables liées sont valides et que vous ne supprimez pas ou ne modifiez pas accidentellement des données liées. Vous pouvez mettre en œuvre l'intégrité référentielle si toutes les conditions suivantes sont réunies :
- Le champ correspondant de la table primaire est une clé primaire ou a un index unique.
- Les champs liés ont le même
type de données.
Il y a deux exceptions. Un champ NuméroAuto peut être lié à un champ Numérique dont la propriété TailleChamp est définie à Entier long, et un champ NuméroAuto dont la propriété TailleChamp est définie avec N° de réplication peut être lié à un champ Numérique dont la propriété TailleChamp est définie à N° de réplication. - Les deux tables appartiennent à la même base de données. Si les tables sont des tables liées, elles doivent être définies au même format, et vous devez ouvrir la base de données dans laquelle elles sont stockées pour activer l'intégrité référentielle. L'intégrité référentielle ne s'applique pas à des tables liées provenant de bases de données utilisant d'autres formats.
Les règles suivantes s'appliquent quand vous utilisez l'intégrité référentielle :
- Dans le champ clé étrangère vous ne pouvez pas entrer une valeur qui n'existe pas dans la clé primaire de la table primaire. Toutefois, vous pouvez entrer une valeur Null dans la clé étrangère pour indiquer que les enregistrements ne sont pas liés.
- Vous ne pouvez pas effacer un enregistrement de la table primaire si des enregistrements correspondants existent dans une table liée.
- Vous ne pouvez pas modifier une valeur clé primaire dans la table primaire si cet enregistrement a des enregistrements liés.
Lorsque vous appliquez l'intégrité référentielle à une relation, vous pouvez spécifier si vous voulez que Access mette à jour en cascade et supprime en cascade automatiquement des enregistrements liés. Si vous activez ces options, les opérations de suppression et de mise à jour qui normalement ne sont pas permises par les règles d'intégrité référentielle sont alors autorisées. Quand vous supprimez des enregistrements ou que vous modifiez des valeurs de clé primaire dans une table primaire, Access effectue les modifications nécessaires dans les tables liées afin de maintenir l'intégrité référentielle.
Si vous activez la case à cocher Mettre à jour en cascade les champs correspondants quand vous définissez une relation, chaque fois que vous modifiez la clé primaire de l'enregistrement d'une table primaire, le logiciel met automatiquement à jour la clé primaire avec la nouvelle valeur dans tous les enregistrements liés. Cette mise à jour en cascade est effectuée sans afficher de message.
Attention: Si la clé primaire dans la table primaire est un champ NuméroAuto, il est inutile d'activer la case à cocher Mettre à jour en cascade les champs correspondants car il est impossible de changer les valeurs d'un champ de type NuméroAuto.
Si vous activez la case à cocher Effacer en cascade les enregistrements correspondants lorsque vous définissez une relation, Microsoft Access supprime automatiquement les enregistrements correspondants dans la table liée à chaque fois que vous supprimez un enregistrement de la table primaire. Lorsque vous supprimez des enregistrements d'un formulaire ou d'une feuille de données alors que la case à cocher Effacer en cascade les enregistrements correspondants est activée, vous êtes prévenu que des enregistrements correspondants peuvent aussi d'être supprimés. Par contre, si vous supprimez des enregistrements à l'aide d'une requête Suppression, les enregistrements sont supprimés automatiquement dans les tables liées sans afficher de message.
- un à plusieurs:
- ConceptionLorsque vous créez une base de
données, vous devez choisir comment regrouper les données. Si vous avez un
doute sur vos choix, utilisez Access pour analyser vos tables: dans le menu
outil, choisir analyse puis tables
- CréationIl y a plusieurs possibilités pour créer une table:
- Requêtes
Vous pouvez utiliser des requêtes pour afficher, modifier et analyser des données de diverses façons. Vous pouvez également les utiliser comme source d'enregistrements pour des formulaires, des états et des pages d'accès aux données.
Il existe plusieurs types de requêtes:
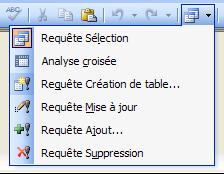
Requêtes Sélection:
la requête Sélection est le type de requête le plus courant. Elle récupère des données contenues dans une ou plusieurs tables et affiche les résultats sous la forme d'une feuille de données dans laquelle il vous est possible d'effectuer une mise à jour des enregistrements (sous réserve de quelques restrictions). Vous pouvez également utiliser une requête Sélection pour regrouper des enregistrements et calculer une somme, une moyenne ou effectuer un comptage ou tout autre type d'opération.Requêtes paramétrées:
une requête paramétrée est une requête qui, lors de son exécution, affiche une boîte de dialogue qui vous invite à entrer des informations, telles que des critères pour extraire des enregistrements ou une valeur à insérer dans un champ. Vous pouvez configurer cette requête afin qu'elle vous invite à entrer plusieurs informations : vous pouvez par exemple la configurer pour qu'elle vous invite à saisir deux dates afin de récupèrer tous les enregistrements compris entre celles-ci.
Les requêtes paramétrées peuvent également servir de base à des formulaires, des états et des pages d'accès aux données. Vous pouvez par exemple créer un état des revenus mensuels basé sur une requête paramétrée. Lorsque vous imprimez l'état, cela affiche une boîte de dialogue qui vous demande le mois sur lequel l'état doit porter. Vous entrez un mois et vous imprimez l'état qui s'y rapporte.Requêtes Analyse croisée:
les requêtes Analyse croisée vous permettent de calculer et de restructurer des données afin d'en faciliter l'analyse. Ces requêtes calculent une somme, une moyenne, un nombre ou tout autre type de total pour des données regroupées en deux types d'informations, dont l'un est situé en bas à gauche de la feuille de données et l'autre, en haut.Requêtes Action:
une requête Action est une requête capable de modifier ou déplacer un grand nombre d'enregistrements en une seule opération. Il existe quatre types de requêtes Action :- Requêtes Suppression
Supprime un groupe d'enregistrements d'une ou plusieurs tables. Par exemple, vous pouvez utiliser une requête Suppression pour effacer des produits qui ne sont plus fabriqués ou qui ne sont plus commandés. Lorsque vous utilisez ce type de requête, vous supprimez toujours des enregistrements entiers, et non uniquement certains champs dans ces enregistrements. - Requêtes Mise à jour
Apporte des changements globaux à un groupe d'enregistrements dans une ou plusieurs tables. Vous pouvez par exemple augmenter vos prix de 10% sur tous vos produits laitiers, ou augmenter de 5% les salaires des personnes appartenant à une certaine catégorie professionnelle. Ce type de requête vous permet de modifier les données contenues dans une table existante. - Requêtes Ajout
Ajoute un groupe d'enregistrements d'une ou de plusieurs tables à la fin d'une ou de plusieurs tables. Supposez, par exemple, que votre clientèle s'élargisse et que vous ayez une base de données qui contient une table d'informations sur ces nouveaux clients. Pour éviter de taper toutes ces informations, vous aimeriez les ajouter à votre tables Clients. - Requêtes Création de table
Crée une table en reprenant totalement ou partiellement les données d'autres tables. Ce type de requête est utile pour créer des tables à exporter vers d'autres bases de données ou une table d'historique contenant d'anciens enregistrements.
Requêtes SQL:
Nous allons regarder certaines de ces requêtes plus en détail:
Requête que vous créez à l'aide d'une instruction SQL. Le langage SQL (Structured Query Language) permet d'interroger, de mettre à jour et de gérer des bases de données relationnelles.
Lorsque vous créez une requête en mode de Création de requête, cela construit en tâche de fond les instructions SQL équivalentes. En fait, la plupart des propriétés de requêtes dans la feuille des propriétés en mode Création de requête ont des clauses équivalentes et des options accessibles en mode SQL. Si vous le souhaitez, vous pouvez afficher ou modifier l'instruction SQL en mode SQL. Toutefois, une fois la requête modifiée en mode SQL, elle risque de ne pas s'afficher comme précédemment en mode Création.- Requête simple (ou requête sélection)
La requête Sélection est le type de requête le plus courant. Vous pouvez l'utiliser pour :
- Extraire les données à partir d'une ou de plusieurs tables en utilisant des critères que vous spécifiez puis en affichant les données selon l'ordre de votre choix.
- Mettre les enregistrements à jour dans la feuille de données d'une requête Sélection (avec certaines restrictions).
- Regrouper les enregistrements et calculer des sommes, des comptes, des moyennes et autres types de totaux.
- Requête Analyse croisée
Vous pouvez utiliser des requêtes Analyse croisée pour calculer et restructurer des données en vue d'une analyse plus simple de vos données. Les requêtes Analyse croisée calculent une somme, une moyenne, un nombre ou un autre type de total pour des données regroupées en deux types d'informations, dont l'un est situé en bas à gauche de la feuille de données et l'autre, en haut.
- Requête Ajout
Une requête d'ajout ajoute un groupe d'enregistrements d'une ou plusieurs
tables à la fin d'une ou de plusieurs tables. Supposez, par exemple, que votre
clientèle s'élargisse et que vous ayez une base de données qui contient une
table d'informations sur ces nouveaux clients. Pour éviter de taper toutes ces
informations, vous aimeriez les ajouter à votre table Clients. Utilisez aussi
les requêtes Ajout pour :
- Ajouter des champs selon certains critères. Il est possible, par exemple, que vous ne vouliez ajouter que les noms et adresses des clients dont les commandes n'ont pas encore été traitées.
- Ajouter des enregistrements lorsque certains champs d'une table n'existent pas dans l'autre table. Par exemple, dans la base de données Les Comptoirs, la table Clients se compose de 11 champs. Supposez que vous souhaitiez ajouter des enregistrements qui proviennent d'une table dont 9 champs seulement correspondent aux champs de votre table Clients. Une requête Ajout ajoutera les données contenues dans les champs correspondants et ignorera les autres.
- Requête suppression
Une requête Suppression supprime un groupe d'enregistrements d'une ou plusieurs tables. Par exemple, vous pouvez utiliser une requête Suppression pour effacer des produits qui ne sont plus fabriqués ou qui ne sont plus commandés. Lorsque vous utilisez une requête Suppression, vous supprimez toujours des enregistrements entiers, et non uniquement certains champs dans ces enregistrements.
Vous pouvez utiliser une requête de suppression pour supprimer les enregistrements d'une seule table, de plusieurs tables ayant une relation un-à-un, ou de plusieurs tables ayant une relation un-à-plusieurs, si vous activez les suppressions en cascade.Considérations importantes à prendre en compte lors de l'utilisation d'une requête Suppression:
- Une fois que vous avez supprimé des enregistrements avec une requête Suppression, vous ne pouvez plus annuler cette opération. En conséquence, il est préférable de visualiser auparavant les données sélectionnées par la requête avant de l'exécuter pour la suppression. Pour cela, cliquez sur le bouton Affichage dans la barre d'outils et visualisez la requête en mode Feuille de données.
- Conservez à tout moment des copies de sauvegarde de vos données. Si vous supprimez des enregistrements par erreur, vous pouvez les extraire de vos copies de sauvegarde.
- Dans certains cas, l'exécution d'une requête de suppression peut provoquer la suppression d'enregistrements dans des tables connexes, même s'ils ne figurent pas dans la requête. Ceci peut se produire lorsque votre requête ne contient que la table du côté « un » d'une relation un-à-plusieurs et que vous avez activé les suppressions en cascade pour cette relation. La suppression d'enregistrements dans la table « un » entraîne la suppression des enregistrements dans la table « plusieurs ».
- Quand une requête Suppression contient plusieurs tables, par exemple quand une requête supprime les enregistrements en doublon dans une des tables, sa propriété EnrUniques doit être définie à Oui.
- Opérations
Vous pouvez créer un champ qui affiche les résultats d'un calcul que vous avez défini dans une expression ou qui manipule les valeurs d'un champ.
- Ouvrez la requête en mode Création.
- Tapez une expression dans une cellule vide de la ligne Champ.
Si l'expression contient un nom de champ, vous devez le placer entre crochets.
Lorsque vous avez appuyé sur ENTRÉE ou que vous vous êtes placé dans une autre cellule, le logiciel entre le nom de champ par défaut ExprN, où N correspond à un entier dont la valeur augmente pour chaque nouveau champ d'expression de la requête. Le nom s'affiche devant l'expression et il est suivi par deux-points. Dans une feuille de données, ce nom correspond à l'en-tête de colonne.
Vous pouvez sélectionner ExprN et taper un nouveau nom plus descriptif, tel que NouveauPrix. - Si l'expression contient une ou plusieurs fonctions d'agrégation Somme (Sum), Moyenne (Avg), (Compte) Count, Min, Max, ÉcartType (StDev) ou Var) et que la grille de création comporte un ou plusieurs autres champs que vous souhaitez utiliser pour le regroupement, cliquez sur Totaux dans la barre d'outils (sauf si la ligne Total est déjà affichée). Conservez Regroupement dans la cellule Opération du champ de regroupement, et dans le champ calculé, remplacez Regroupement par Expression.
- CritèresVous pouvez utiliser de nombreux
critères pour trier/filtrer les enregistrements présents dans une requête. Pour
cela, vous pouvez entrer les conditions à la main ou utiliser le générateur
d'expression (en se plaçant dans la case critère, et en choisissant créer dans
le menu accessible par clic droit):
- générateur d'expression
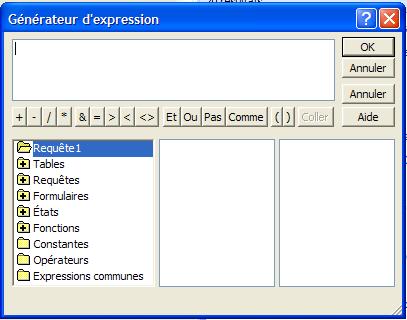
Le Générateur d'expression comprend trois sections, disposées de haut en bas :
Zone Expression
Dans la section supérieure du générateur se trouve une zone Expression où vous construisez l'expression. Utilisez la zone inférieure du générateur pour créer les éléments de l'expression, puis collez ces éléments dans la zone Expression pour former une expression. Vous pouvez également saisir des parties de l'expression directement dans la zone Expression.
Boutons Opérateur
Dans la section du milieu du générateur se trouvent des boutons pour les opérateurs les plus courants. Si vous cliquez sur un de ces boutons Opérateur, le Générateur d'expression insère l'opérateur au point d'insertion de la zone Expression. Pour une liste complète des opérateurs que vous pouvez utiliser dans des expressions, cliquez sur le dossier Opérateurs dans la zone inférieure gauche et sur la catégorie d'opérateurs appropriée dans la zone du milieu. La zone de droite présente tous les opérateurs de la catégorie sélectionnée.
Éléments de l'Expression
Il y a trois zones dans la section inférieure du Générateur :- La zone de gauche contient des dossiers qui listent les objets table, requête, formulaire et état de la base de données, les fonctions prédéfinies et définies par l'utilisateur, les constantes les opérateurs, et les expressions courantes.
- La zone du milieu présente les éléments ou catégories d'éléments du dossier sélectionné dans la zone de gauche. Par exemple, si vous cliquez sur Fonctions intégrées dans la zone de gauche, la zone du milieu affiche les catégories de fonctions de Microsoft Access.
- La zone de droite répertorie les valeurs, s'il y en a, des éléments que vous avez sélectionnés dans les zones de gauche et du milieu. Par exemple, si vous cliquez sur Fonctions intégrées dans la zone de gauche et sur une catégorie de fonctions dans la zone du milieu, la zone de droite présente toutes les fonctions intégrées de la catégorie considérée.
- expression manuelle
Les crochets ([ ]) autour d'un champ, d'un contrôle, ou d'une propriété dans
un identificateur indiquent que l'élément est le nom d'une table, d'une
requête, d'un formulaire, d'un état, d'un champ ou d'un contrôle.
Lorsque vous tapez un nom d'objet dans un identificateur, vous devez le placer entre crochets s'il contient un espace ou un caractère spécial tel que le caractère « trait de soulignement » (_). Si ce nom ne contient ni espace ni caractère spécial, vous pouvez le saisir sans crochets. Ils sont ajoutés automatiquement (sauf dans les deux cas indiqués plus loin).
Par exemple, vous pouvez taper l'expression suivante pour calculer la somme des valeurs des champs Transport et MontantCommande : = Transport + MontantCommande et l'expression s'affiche comme suit : = [Transport] + [MontantCommande].
Si vous tapez une expression plus longue que la zone de saisie standard dans une feuille des propriétés, une grille de conception ou un argument d'action, vous pouvez saisir l'expression dans la zone Zoom. Pour ouvrir la zone Zoom, appuyez sur MAJ+F2 quand le focus se trouve là où vous voulez saisir l'expression.
- générateur d'expression
- Requêtes Suppression
- Formulaires
- Présentation générale
Un formulaire est un type d'objets de base de données qui est utilisé essentiellement pour entrer et afficher des données dans une base de données. Vous pouvez également utiliser un formulaire comme Menu général qui ouvre d'autres formulaires et des états dans la base de données ou comme boîte de dialogue personnalisée qui permet aux utilisateurs d'entrer des données et de les utiliser.
Il y a plusieurs façons de créer un formulaire, par exemple.
- Basé sur une table ou une requête unique
en utilisant la fonctionnalité de Formulaire instantanée:
le Formulaire instantané crée un formulaire reprenant tous les champs et enregistrements de la table ou de la requête sous-jacente. Si des tables ou des requêtes sont liées à la source d'enregistrements, le formulaire contiendra aussi l'ensemble de ces champs et enregistrements. - Basé sur une ou plusieurs tables ou requêtes à l'aide d'un Assistant: l'Assistant vous pose des questions détaillées sur les sources d'enregistrement, les champs, la présentation et format souhaités, puis crée un formulaire sur la base de vos réponses.
- Directement en mode création:
vous pouvez créer un formulaire de base et le personnaliser en mode création pour satisfaire vos exigences.
Il en existe d'autres:
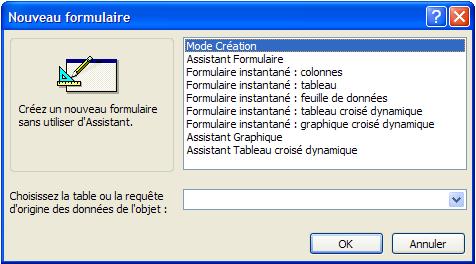
Astuce: il est possible d'afficher un formulaire ou une page d'accès aux données au démarrage, de deux manières différentes:
- en utilisant Access:
- Dans le menu Outils, cliquez sur Démarrage.
- Dans la zone Afficher formulaire/page, cliquez sur un formulaire ou une page d'accès aux données.
- en créant une macro
Remarques
- Les modifications apportées à ces paramètres dans la boîte de dialogue Démarrage ne prennent effet qu'à la prochaine ouverture de la base.
On peut associer plusieurs événements au formulaire:
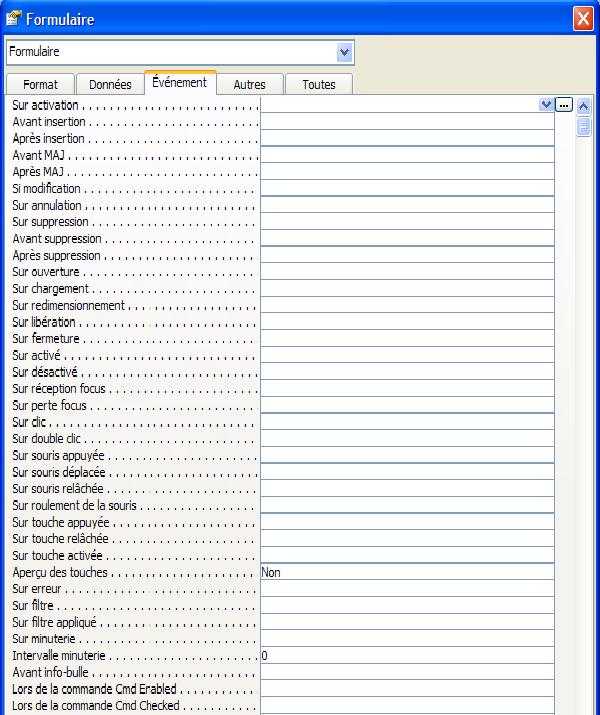
EVENEMENT
QUAND SE PRODUIT-IL ?
Sur Activation Dès qu'un autre enregistrement apparaît à l'écran Avant insertion a à la frappe du premier caractère d'un nouvel enregistrement, ou à la première entrée dans une liste déroulante d'un nouvel enregistrement Après insertion Juste après que l'enregistrement ait été sauvegardé Avant MAJ Juste avant d'écrire les modifications sur disque Après MAJ Juste après avoir écrit les modifications sur disque Sur Suppression S'exécute dès l'appui de DEL Avant Suppression S'exécute Avant d'effacer l'enregistrement, juste avant la boîte de dialogue de confirmation Après suppression Juste après une quelconque réponse à la boîte de dialogue de confirmation de suppression Sur ouverture A l'ouverture du formulaire (pas à l'agrandissement ni à l'activation), juste avant de l'afficher. Se passe juste avant Chargement Sur chargement Se passe juste après Sur Ouverture Sur redimensionnement Juste après le redimensionnement. Attention : Lors d'un chargement de formulaire, cet événement peut se produire plusieurs fois. Sur libération Sur fermeture A la fermeture du formulaire (pas à la diminution ni à la désactivation), juste avant de le faire disparaître Sur activé Dès que le formulaire est activé Sur désactivé Juste après avoir cliqué sur une autre feuille (ce qui désactive automatiquement le formulaire) Sur réception focus Devrait se passer chaque fois que le formulaire devient actif, mais je n'arrive pas à déclencher l'événement Sur perte focus Même problème qu'avec Réception focus Sur clic Cliquer oú ??? Sur double clic double-Cliquer oú ??? Sur souris appuyée Sur souris déplacée Se passe perpétuellement Sur souris relâchée Sur touche appuyée A la place d'entrer le caractère à l'endroit voulu Sur touche activée Sur touche relâchée Juste après avoir entré le caractère Sur erreur Dès qu'on tente de valider un champ non-correct (par exemple). Juste avant la boîte de dialogue par défaut. Sur minuterie Dès que l'intervalle minuterie est terminée Intervalle minuterie Se compte en millisecondes (0-65535) Ces événements sont associés à une procédure événementielle.
Cette procédure événementielle est écrite en Visual Basic:
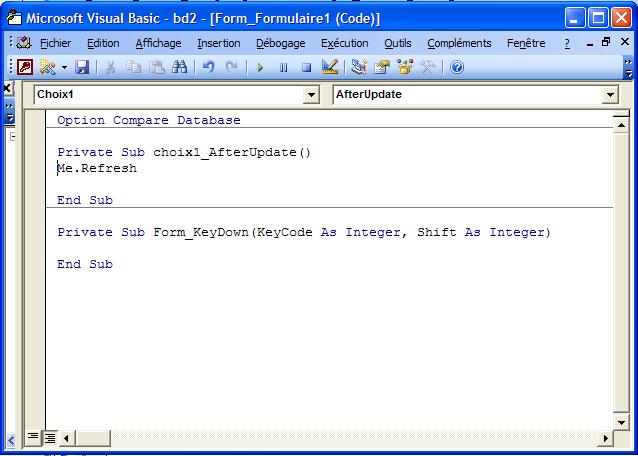
Me représente l'objet en cours.
L'événement Sur Touche Appuyée est bien pratique. Elle se compose de 2 paramètres : Keycode et Shift. On ne peut pas faire grand chose de correct quand on teste la valeur d'une lettre ou d'un chiffre, mais bien quand on utilise les touches de contrôle telles que Ctrl, Shift, Alt et AltGr
Touches enfoncées Valeur de Keycode Valeur de Shift Ctrl 17 2 Shift 16 1 Alt 18 4 AltGr 18 6 Ctrl Shift 16 3 Ctrl Alt 18 6 (pareil que AltGr, mais à l'infini) Ctrl AltGr 18 6 Shift Alt 18 5 Shift AltGr 18 7 Ctrl Shift Alt 18 7 Ctrl Shift AltGr 18 7 - Basé sur une table ou une requête unique
en utilisant la fonctionnalité de Formulaire instantanée:
- Boite à outils
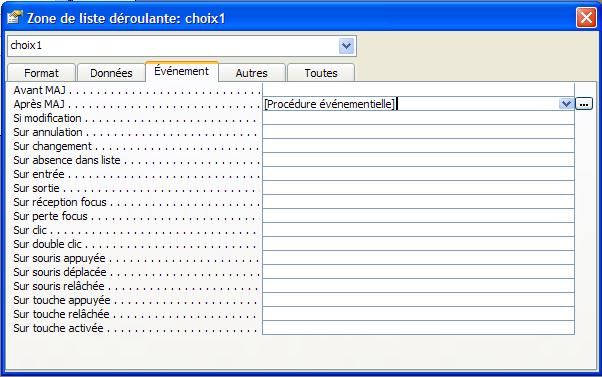
Les listes déroulantes permettent d'effectuer des choix. On peut cascader plusieurs formulaires :
En utilisant une petite ligne de code, on peut amener les listes déroulantes à se mettre à jour, par exemple en rechargeant le formulaire avec l'instruction REFRESH :
Pour rafraîchir une liste déroulante d'un formulaire (en fait pour réinterroger la base de données), on peut aussi utiliser la méthode REQUERY de la façon suivante. Dans notre exemple, nous sommes dans un formulaire principal, et dans le sous-formulaire il existe une liste déroulante basée sur la table des articles. L'idée est que cette liste déroulante ne doit comporter que les articles vendus par le fournisseur dont le numéro se trouve dans le formulaire principal. Il est alors nélcessaire de rafraîchir cette liste à chaque MAJ de la liste déroulante du formulaire principal. Le code de l'exemple suivant est à placer SUR RECEPTION FOCUS de la liste en question
Exemple :
Me![DésignationDuSous-Formulaire].Formulaire![ListeDéroulanteArticle].Requery
On peut associer un événement à plusieurs actions, pas seulement à la mise à jour :
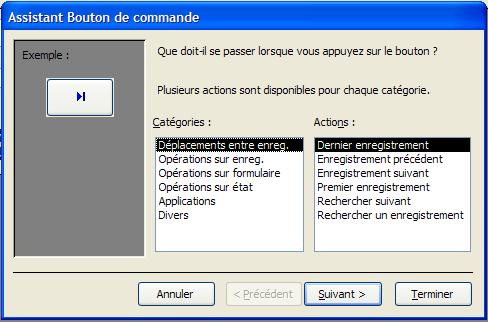
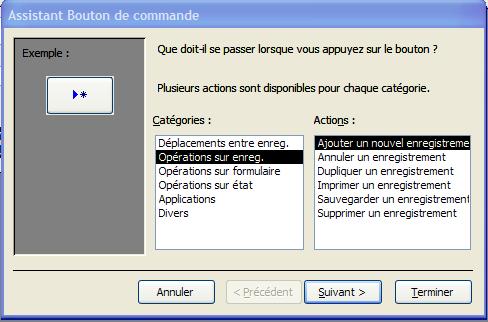
Boutons de commande On peut associer de nombreuses actions à un bouton de commande:
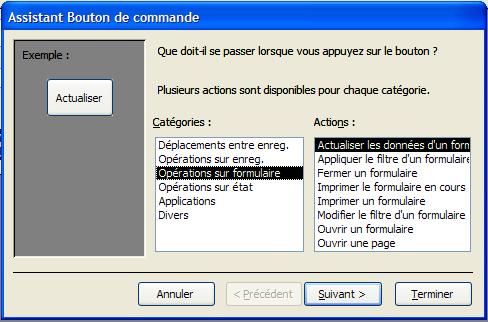
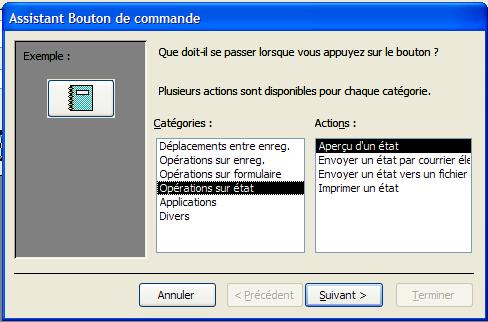
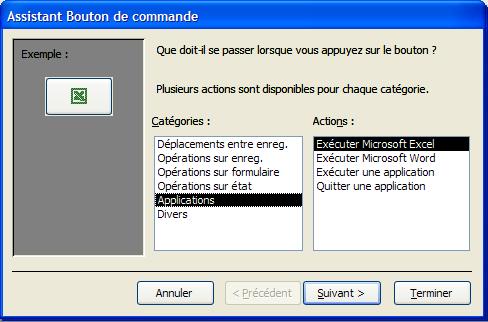
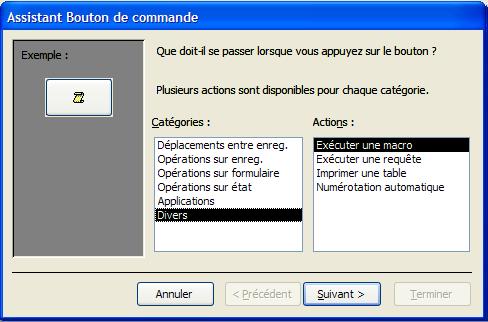
Un sous-formulaire est un formulaire inséré dans un autre formulaire. Le formulaire primaire est appelé formulaire principal et le formulaire qu'il contient, sous-formulaire. Une combinaison formulaire/sous-formulaire est souvent appelée formulaire hiérarchique ou formulaire père/fils.
Les sous-formulaires sont particulièrement utiles lorsque vous voulez afficher les données de tables ou de requêtes qui ont une relation un-à-plusieurs. Le formulaire principal affiche les données du côté « un » de la relation. Le sous-formulaire affiche les données du côté « plusieurs » de la relation.
Dans ce type de formulaire, le formulaire principal et le sous-formulaire sont liés. Ainsi, le sous-formulaire n'affiche que les enregistrements qui correspondent à l'enregistrement en cours du formulaire principal.
Lorsque vous créez un sous-formulaire, vous pouvez le concevoir de façon à s'afficher en modes Feuille de données, Formulaire, Tableau croisé dynamique ou Graphique croisé dynamique. Vous pouvez également définir le mode d'affichage par défaut du sous-formulaire et désactiver un ou plusieurs modes d'affichage. Vous pouvez changer le mode d'affichage d'un sous-formulaire lorsque le formulaire principal est affiché en mode Formulaire.Les sous-formulaires ne s'affichent pas lorsqu'un formulaire principal est ouvert en affichage Tableau croisé dynamique ou Graphique croisé dynamique.
Vous pouvez faire en sorte qu'un formulaire affiché en mode Formulaire ressemble à une feuille de données, mais comme il est en mode Formulaire, il peut afficher un en-tête ou un pied de page de formulaire.
Lorsque vous créez un formulaire et un sous-formulaire basés sur des tables qui ont une relation un-à-plusieurs, le formulaire principal représente le côté « un » de la relation et les sous-formulaires le côté « plusieurs » de la relation. Le formulaire principal est synchronisé avec le sous-formulaire de façon que le sous-formulaire n'affiche que les enregistrements associés à l'enregistrement du formulaire principal.
Si vous faites appel à un Assistant pour créer un sous-formulaire, ou si vous faites glisser un formulaire, une table ou une requête vers un autre formulaire afin de créer un sous-formulaire, Access synchronise automatiquement le formulaire principal et le sous-formulaire si l'une des conditions suivantes est respectée :
- Vous avez défini des relations pour les tables que vous sélectionnez ou qui sont sous-jacentes aux requêtes sélectionnées.
- Le formulaire principal est basé sur une table possédant une clé primaire et le sous-formulaire est basé sur une table contenant un champ dont le nom est identique à cette clé primaire et dont le type de donnée et la taille du champ sont identiques ou compatibles. Par exemple, dans une base de données Microsoft Access, si la clé primaire de la table sous-jacente au formulaire principal est un champ NuméroAuto et si sa propriété FieldSize est définie sur Entier long, le champ correspondant de la table sous-jacente au sous-formulaire doit être un champ Numérique dont la propriété FieldSize est définie sur Entier long. Si vous sélectionnez une ou plusieurs requêtes, la table sous-jacente de ces requêtes doit remplir ces conditions.
Un formulaire principal peut contenir autant de sous-formulaires que vous le souhaitez à condition qu'ils soient placés dans le formulaire principal. Vous pouvez également imbriquer jusqu'à sept sous-formulaires. Cela signifie que vous pouvez avoir un sous-formulaire contenu dans un formulaire principal mais aussi un second sous-formulaire contenu dans ce sous-formulaire, etc. Vous pouvez, par exemple, avoir un formulaire principal qui affiche les clients, un sous-formulaire qui affiche les commandes et un autre sous-formulaire qui affiche les détails des commandes. Un formulaire n'affiche cependant pas de sous-formulaires en mode Tableau croisé dynamique ou Graphique croisé dynamique.
Lorsque vous utilisez un formulaire possédant un sous-formulaire pour entrer de nouveaux enregistrements, Microsoft Access sauvegarde l'enregistrement en cours dans le formulaire principal lorsque vous saisissez des données dans le sous-formulaire. Grâce à cela, les enregistrements de la table « plusieurs » pourront être reliés à un enregistrement de la table « un ». Chaque enregistrement est également automatiquement sauvegardé lorsqu'il est ajouté au sous-formulaire.
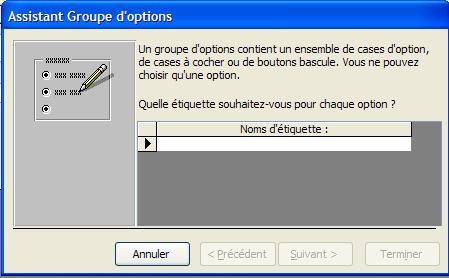
Groupe d'options
On peut lier plusieurs cases à cocher ensemble afin de proposer un choix multiple:
- Présentation générale
- États
Si dans un tableur, l'impression est directe (via la commande imprimer du menu Fichier), ce n'est pas le cas des bases de données (SGBD). L'impression d'un rapport passe par la création préalable d'un état. Ces états permettent de faire (outre l'affichage des champs) des tris et des filtres sur les enregistrements. La dernière possibilité des états va permettre également de créer des sous-totaux et des totaux sur les résultats imprimés. Les états reprennent donc les calculs repris par les fonctions d'un tableur.
Mais la création d'un état qui présente correctement les données imprimées est souvent une opération longue et quelque peu fastidieuse. C'est pourquoi l'état n'est pas toujours considéré comme indispensable, et il existe deux façons de s'en passer.
- Première solution
Nous pouvons imprimer directement une table ou une feuille de données, à condition de limiter considérablement nos ambitions en matière de présentation. Nous sommes maîtres de la largeur des colonnes (ne pas lésiner sur ce point, sinon l'information risque d'être tronquée), de la couleur de fond de cellule, de la taille et du type de la police, et c'est à peu près tout. Le SGBD pagine, affiche la date et le nom de la table (ou de la feuille de données), et met en page à sa façon -- c'est à dire qu'il commence en haut et à gauche, tout simplement. Imprimer directement une table ou une feuille de données est une solution de dépannage, mais ce n'est pas vraiment le moyen de réaliser un document bien présenté. - Deuxième solution
. Une table créée dans Access et dans d'autres SGBD fonctionnant sous le système d'exploitation Windows peut facilement être exportée vers un tableur, et en particulier vers Excel qui est le plus utilisé. Dans un tableur, la mise en page avant impression est facile et intuitive, et nous disposons là d'un bon moyen pour obtenir un imprimé correctement présenté. L'exportation vers Excel des résultats d'une requête constitue une technique de plus en plus utilisée, non seulement pour mettre en forme des données avant impression, mais aussi pour profiter des diverses fonctions qu'offre le tableur. L'opération est particulièrement facile si nous nous trouvons dans Access : la table à analyser ou à imprimer étant sélectionnée, nous cliquons dans le menu sur "Outils", puis sur "Liaisons Office"et enfin sur "Analyse avec Microsoft Excel". Le tableur s'ouvre, et la table y est aussitôt exportée. De plus, un fichier au format Excel est enregistré sur le bureau.
Un état est pratiquement toujours construit sur le résultat d'une requête, et ce pour les raisons suivantes :
- les bases de données contiennent souvent des quantités considérables d'information, et il n'est pas question de tout imprimer. Il faut donc commencer par sélectionner l'information particulière que l'on veut reproduire avant d'imprimer ;
- dans une BDD relationnelle, l'information est répartie dans des tables multiples, et il faut la rassembler avant de l'imprimer. On peut, cependant, introduire dans un même état des champs provenant de plusieurs tables, à condition que ces dernières soient liées par des relations ;
- on peut désirer que l'information imprimée se présente dans un certain ordre. Il faut donc opérer un tri plus ou moins complexe avant d'imprimer. Ceci dit, on peut également demander un tri complexe (jusqu'à quatre niveaux) lors de la création de l'état.
- Bien qu'il ne soit pas question, en général, d'imprimer la totalité du contenu d'une BDD, un état s'étale souvent sur plusieurs pages. C'est le SGBD qui se charge de gérer les sauts de page (si l'utilisateur ne donne pas d'instructions particulières à ce sujet), d'imprimer l'en-tête et le pied de chaque page. L'en-tête de la première page, et la fin de la dernière page, sont généralement différents de ceux des autres pages.
- Avant de créer un état
La finalité de l'état étant la réalisation d'une sortie
imprimée, il est indispensable d'indiquer au SGBD :
- l'imprimante utilisée
- la taille de la zone imprimable, c'est à dire celle du papier, diminuée de celle des marges.
- L'imprimante
Le SGBD construit l'état en fonction des caractéristiques de l'imprimante par défaut. Si vous utilisez un poste de travail sur lequel aucune imprimante n'a été déclarée, vous allez au-devant de bien des ennuis (lenteur, plantage...). Vérifiez donc ce point avant d'entreprendre la création d'un état. -
La zone imprimable
Ensuite, le SGBD tient compte des options que vous avez choisies -- ou, plus généralement, conservées par défaut -- en ce qui concerne la taille du papier (A4, sauf exception) et les marges d'impression. Si vous manquez de place en largeur -- ce qui est souvent le cas lorsqu'un état est présenté en colonnes -- vous avez intérêt à réduire les marges à gauche et à droite. Mais attention ! vous devez effectuer cette opération avant de commencer à construire votre état. Une fois ce dernier créé, les changements de marge que vous effectuez sont sans effet sur lui.
Dans Access, pour régler les marges, cliquez dans le menu sur "Outils", puis "Options..." : la fenêtre "Options" s'ouvre. Choisissez l'onglet "Général" : les quatre marges sont réglées par défaut à un pouce (2,54 cm). En pratique, 2 cm à gauche et 1 cm à droite suffisent largement. Quelles que soient les valeurs que vous choisissez, elles resteront valables quelle que soit la BDD dans laquelle vous travaillez, tant que vous ne les modifierez pas à nouveau. - La sélection des données
Mettez au point la (ou les) requête(s) qui vous permettent de sélectionner les données à imprimer. Si vous avez besoin d'un tri, incorporez-le à ce stade, car les tris que l'on demande au niveau des états ne fonctionnent pas toujours très bien. Enfin, vous n'êtes pas obligé de créer une table, un état pouvant être construit directement sur le résultat d'une requête.
- Création
Il existe plusieurs manières pour créer un état et plusieurs types d'état:
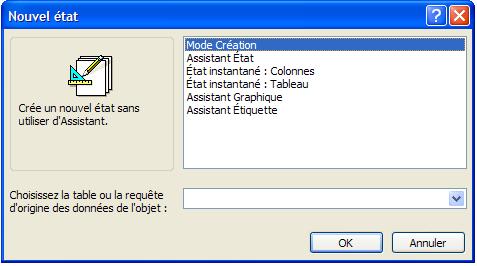
Il existe trois méthodes de création d'état.
À partir d'une table ou d'une requête unique en utilisant l'État Instantané.
L'État Instantané crée un état affichant tous les champs et enregistrements de la requête ou de la table sous-jacente.- Dans la fenêtre Base de données, cliquez sur États sous Objets.
- Cliquez sur le bouton Nouveau dans la barre d'outils de la fenêtre Base de données.
- Dans la boîte de dialogue Nouvel état, cliquez sur
l'un des Assistants suivants :
- État instantané : Colonne simple
Chaque champ apparaît sur une ligne distincte avec, à sa gauche, une étiquette. - État instantané : Tabulaire
Les champs des enregistrements apparaissent sur une ligne et les étiquettes s'impriment dans le haut de la page.
- État instantané : Colonne simple
- Cliquez sur la table ou la requête contenant les données à partir desquelles vous voulez créer l'état.
- Cliquez sur OK.
Access applique le dernier format automatique que vous avez utilisé dans l'état. Si vous créez pour la première fois un état à l'aide d'un Assistant ou si vous n'avez pas utilisé la commande Format automatique du menu Format, Access utilise le format automatique standard.
Vous pouvez aussi créer un état à colonne simple basé sur la table ou la requête ouverte ou sur la table ou la requête sélectionnée dans la fenêtre Base de données. Cliquez sur État instantané dans le menu Insertion, ou sur la flèche placée en regard du bouton Nouvel objet dans la barre d'outils, puis cliquez sur État instantané. Les états créés à l'aide de cette méthode ne possèdent ni en-tête et pied d'état ni en-tête et pied de page.
Basé sur une ou plusieurs tables ou requêtes en utilisant un Assistant.
L'Assistant vous pose des questions détaillées sur les sources d'enregistrement, les champs, la présentation et le format que vous souhaitez utiliser, puis crée un état sur la base de vos réponses.- Dans la fenêtre Base de données, cliquez sur États sous Objets.
- Cliquez sur le bouton Nouveau dans la barre d'outils de la fenêtre Base de données.
- Dans la boîte de dialogue Nouvel état, sélectionnez l'Assistant que vous voulez utiliser. Une description de l'Assistant apparaît dans la partie gauche de la boîte de dialogue.
- Cliquez sur la table ou la
requête contenant les données à partir desquelles vous voulez créer
l'état.
Remarque Vous n'avez pas besoin d'effectuer cette étape si vous cliquez sur l'option Assistant Formulaire lors de l'étape 3 (vous pouvez spécifier l'origine des enregistrements de l'état dans l'Assistant). - Cliquez sur OK.
- Suivez les instructions de l'Assistant.
Si la présentation de l'état créé ne vous satisfait pas, vous pouvez le modifier en mode Création.
Remarques
- Si vous voulez inclure des champs à partir de plusieurs tables et requêtes dans votre état, ne cliquez pas sur Suivant ou Terminer après la sélection des champs de la première table ou requête dans l'Assistant État. Répétez les étapes pour sélectionner une table ou une requête, et sélectionnez les champs que vous voulez inclure dans l'état, jusqu'à la sélection de tous les champs requis.
- Si vous cliquez sur l'une des options État instantané, Access utilise le format automatique que vous avez spécifié en dernier, que ce soit par l'Assistant État ou par la commande Format automatique du menu Format en mode Création.
Dans votre propre mode Création.
Vous créez un état de base et le personnalisez en mode Création pour qu'il convienne à vos exigences.- Dans la fenêtre Base de données, cliquez sur États sous Objets.
- Cliquez sur le bouton Nouveau dans la barre d'outils de la fenêtre Base de données.
- Dans la boîte de dialogue Nouvel état, cliquez sur Mode Création.
- Cliquez sur la table ou sur la
requête contenant les données sur lesquelles vous voulez baser votre
état. (Si vous voulez un
état indépendant, ne sélectionnez rien dans cette liste.).
Si vous souhaitez créer un état qui extrait des données dans plusieurs tables, créez votre état à partir d'une requête. - Cliquez sur OK.
Access affiche l'état en mode Création.
- La boite à outils
La boite à outils est identique à la boite à outils du formulaire. Il faut noter
que certains outils ne sont plus utiles (menus déroulants par exemple).
Par contre, il y a quelques nouveaux icônes dans la barre à outils création.
L'icône trier et grouper notamment à son importance pour créer des groupes de données, et pour leur associer des en-têtes et des pieds de groupe correspondant. - Les sections
Les informations d'un état peuvent être divisées en sections. Tous les états
possèdent une section de détails, mais un état peut également inclure une
section en-tête d'état, en-tête de page, pied de page, et pied d'état. Chaque
section possède une utilité spécifique et est imprimée selon un ordre prévisible
dans l'état.
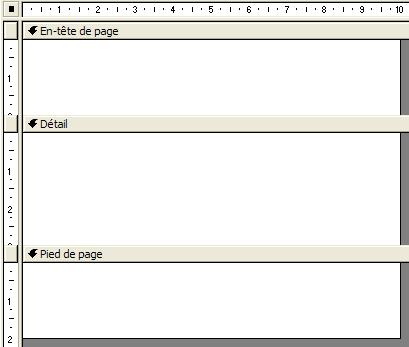

En mode Création, les sections sont représentées sous forme de bandes, et chaque section de l'état est représentée une seule fois. Dans un état imprimé, certaines sections peuvent être répétées. Vous déterminez où apparaissent les informations dans chaque section en plaçant des contrôles, tels que des étiquettes et des zones de texte.
L'en-tête d'état apparaît une fois au début d'un état. Vous pouvez l'utiliser pour des éléments tels qu'un logo, un titre d'état ou une date d'impression. L'en-tête d'état est imprimé avant celui de la page, sur la première page de l'état.L'en-tête de page apparaît dans la partie supérieure de chaque page d'un état. Il permet d'afficher des éléments tels que les en-têtes de colonne.
La section Détail contient le corps principal des données d'un état. Cette section est répétée pour chaque enregistrement dans la source d'enregistrement sous-jacente de l'état.
Le pied de page apparaît dans la partie inférieure de chaque page d'un état. Il permet d'afficher des éléments tels que les numéros de page.Le pied d'état apparaît une seule fois à la fin d'un état. Il permet d'afficher des détails tels que les totaux d'état. Le pied d'état constitue la dernière section dans la conception d'état, mais apparaît avant le pied de page sur la dernière page de l'état imprimé.
Vous pouvez ajouter un en-tête et un pied à chaque groupe d'un état. Dans un état, des commandes expédiées le même jour sont regroupées. L'en-tête affiche la valeur à partir de laquelle les enregistrements sont regroupés, et le pied un sous-total pour le groupe.
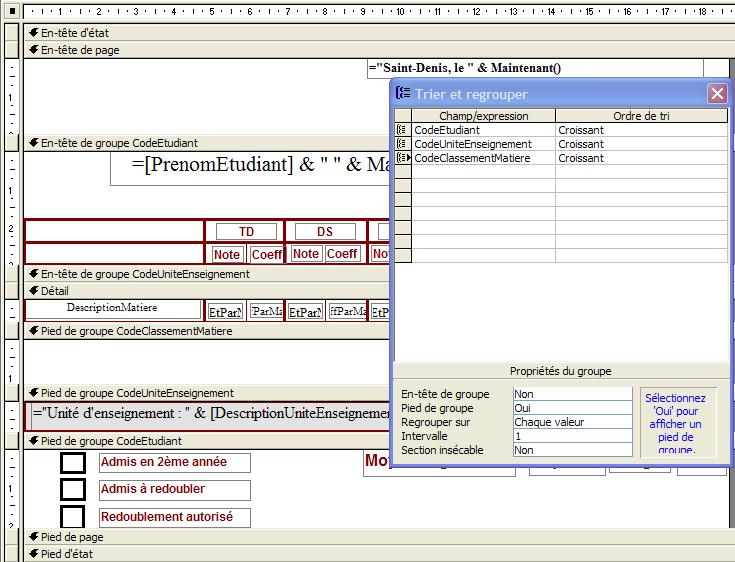
Un en-tête de groupe apparaît au début d'un nouveau groupe d'enregistrements. Il permet d'afficher des informations concernant le groupe de manière globale, telles qu'un nom de groupe.
Un pied de groupe apparaît à la fin d'un groupe d'enregistrements. Il permet d'afficher des éléments tels que les totaux de groupes.
Vous pouvez masquer ou redimensionner une section, ajouter une image, ou définir une couleur d'arrière-plan d'une section. Vous pouvez également définir des propriétés de section pour personnaliser l'impression du contenu d'une section.
La création de groupe permet également d'insérer des sauts de pages, de rajouter des lignes de séparation ou de décider si une section peut être coupée par un saut de page ou pas :
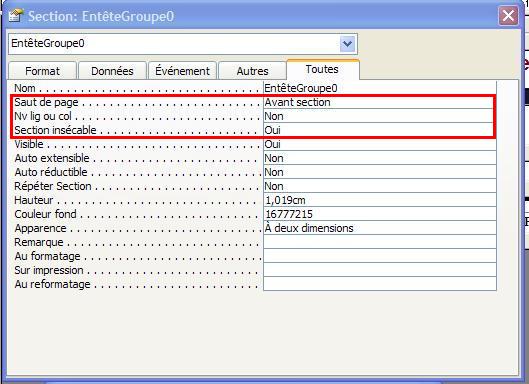
Dans chaque section,on distingue trois catégories de zone de texte :
- la zone de texte dépendante
Son contenu provient soit d'un champ de la table ou de la requête sous-jacente, soit d'une instruction SQL. Les zones de texte dépendantes se trouvent généralement dans la zone "Détail" de l'état ; -
la zone de texte indépendante
Son contenu ne provient pas d'un objet de la BDD. On l'utilise pour afficher un texte informatif (exemple : le titre de l'état), une image (exemple : le logo de l'entreprise), ou des éléments de décoration, principalement dans l'en-tête de l'état ; - la zone de texte calculée
Elle contient le résultat d'un calcul (exemples : somme, moyenne, fonctions statistiques, date, page, etc.). Ce résultat est remis à jour chaque fois que les données utilisées dans le calcul sont modifiées. Les zones de texte calculées se trouvent généralement dans les pieds de page ou dans le pied de l'état.
- la zone de texte dépendante
- Numéro incrémental
Il est possible d'ajouter un champ de numéro incrémental à chaque
enregistrement de la secton détail:
- Ouvrez l'état en mode Création.
- Cliquez sur Zone de texte dans la boîte à outils, puis sur la section Détail où vous souhaitez ajouter la zone de texte.
- Sélectionnez la zone de texte, puis cliquez sur Propriétés dans la barre d'outils.
- Attribuez la valeur =1 à la propriété SourceContrôle (ControlSource).
- Effectuez l'une des actions suivantes :
Pour numéroter chaque enregistrement et réinitialiser le compteur à 1 pour chaque groupe, attribuez la valeur Par groupe (Over Group) à la propriété Cumul (RunningSum).
Pour numéroter chaque enregistrement sans réinitialiser le compteur pour chaque groupe, attribuez la valeur En continu (Over All) à la propriété Cumul (RunningSum).
- Compter le nombre d'enregistrements
On peut compter le nombre d'enregistrements dans chaque groupe ou état:
- Ouvrez l'état en mode Création.
- Effectuez l'une ou/et l'autre des actions suivantes :
- Compter le nombre d'enregistrements dans un groupe
- Cliquez sur l'outil Zone de texte dans la boîte à outils, puis sur la section Détail. Dans la mesure où le contrôle ne sera pas visible pour l'utilisateur, son emplacement dans la section importe peu.
- Sélectionnez la zone de texte, puis cliquez sur Propriétés dans la barre d'outils.
- Définissez les propriétés suivantes :
Propriété Paramètre Nom (Name) Une chaîne de texte, telle que RecordCount SourceContrôle (ControlSource) =1 Cumul (RunningSum) Par groupe Visible (Visible) Non - Ajoutez une zone de texte au pied de groupe.
- Sélectionnez la zone de texte, puis cliquez sur Propriétés dans la barre d'outils.
- Attribuez à la propriété SourceContrôle (ControlSource) le nom du contrôle de la section Détail qui effectue le suivi d'un calcul en cours. Par exemple, =[RecordCount]
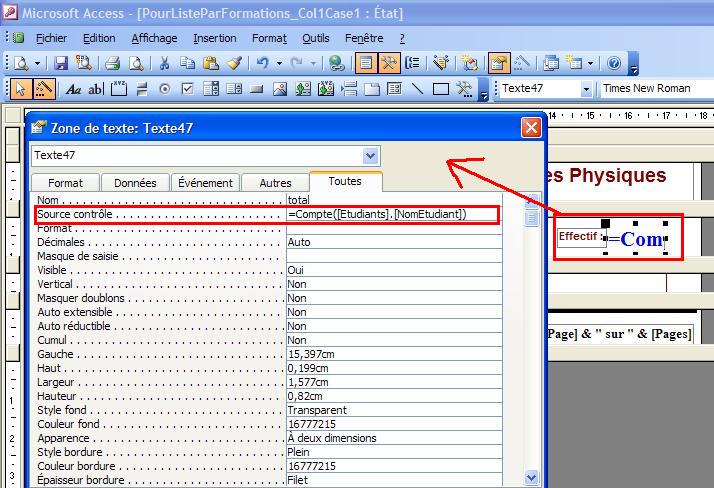
- Compter
le nombre d'enregistrements dans un état
- Cliquez sur l'outil Zone de texte dans la boîte à outils, puis sur la section d'état ou de pied où vous souhaitez placer la zone de texte.
- Sélectionnez la zone de texte, puis cliquez sur Propriétés dans la barre d'outils.
- Attribuez à la propriété SourceContrôle (ControlSource)
de la zone de texte l'expression =Compte(*).
Cette expression utilise la fonction Compte (Count) pour compter tous les enregistrements dans l'état même si certains champs sont de type Null.
- Compter le nombre d'enregistrements dans un groupe
- Afficher une photo d'identité
La difficulté consiste à changer l'image à chaque personne. On utilise pour cela
du code VBA.
Il faut d'abord créer un état comprenant un champ identifiant la personne (sur notre exemple, ce sera le champ CodeEtudiant). Ce champ ne sera pas forcément visible.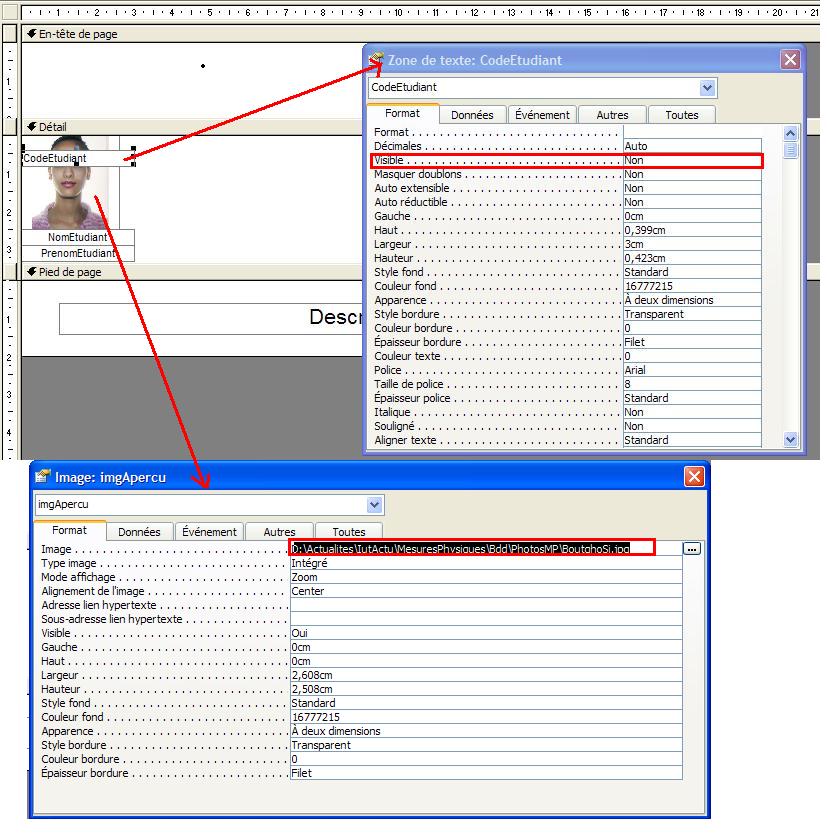 Il faut ensuite afficher une image, et créer un code VBA permettant de changer
cette image pour chaque personne. Sur notre exemple, le nom du fichier image
correspondra au CodeEtudiant. On fera attention à bien préciser le chemin
absolu pour parvenir au fichier. On associera tout cela à la propriété
Format de la section Détail du formulaire.
Il faut ensuite afficher une image, et créer un code VBA permettant de changer
cette image pour chaque personne. Sur notre exemple, le nom du fichier image
correspondra au CodeEtudiant. On fera attention à bien préciser le chemin
absolu pour parvenir au fichier. On associera tout cela à la propriété
Format de la section Détail du formulaire.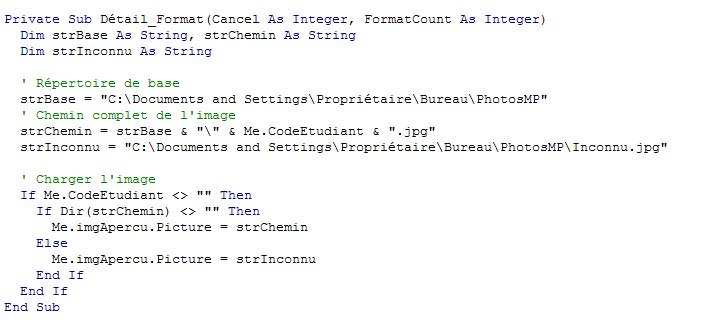
- Date, heure et nombre de pages On peut ajouter la date et l'heure à un état, ainsi que le nombre de pages:
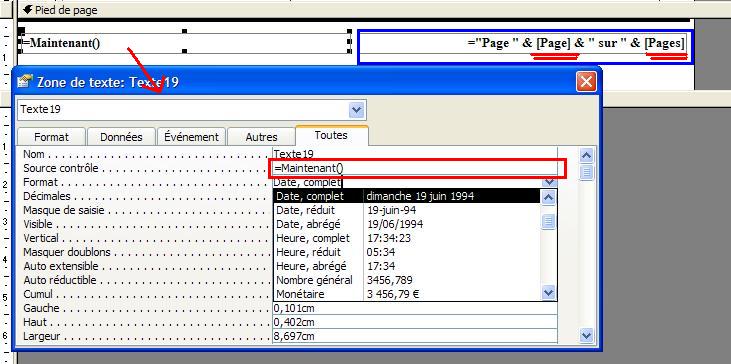
On peut donc préciser le format de la date.
Attention, la commande [Page] donne le numéro de la page en cours, alors que la commande [Pages] correspond au nombre total de pages.
- Première solution
- Pages
- Macros
Une macro reprend une ou plusieurs commandes Access exécutées les unes à la suite des autres, chacune exécutant une tâche précise. Les actions exécutées peuvent être l'ouverture (la fermeture) d'un formulaire, imprimer un état ou rafraîchir la fenêtre en cours par une procédure événementielle.
Une macro peut par exemple:- ouvrir un nouveau formulaire et fermer le précédent
- Actualiser le contenu d'un formulaire
- ...
- Créer une macro ou un groupe de macros
Vous pouvez créer une
macro pour effectuer une action spécifique ou un
groupe de macros pour réaliser des séries d'actions.
Créer une macro
- Dans la fenêtre Base de données, sous Objets, cliquez sur Macros .
- Cliquez sur le bouton Nouveau de la barre d'outils de la fenêtre Base de données.
- Ajoutez une
action à la macro:
- Dans la fenêtre Macro, cliquez sur la première ligne vide de la colonne Action. Si vous souhaitez insérer une action entre deux lignes d'action, cliquez sur le sélecteur de la ligne d'action située directement sous la ligne où vous souhaitez insérer la nouvelle action, puis cliquez sur Insérer une ligne dans la barre d'outils.
- Dans la colonne Action, cliquez sur la flèche pour afficher la liste d'actions.
- Cliquez sur l'action que vous voulez utiliser.
- Dans la partie inférieure de la fenêtre, spécifiez les arguments de l'action, si nécessaire. Dans le cas d'arguments d'action dont la définition correspond à un nom d'objet de base de données, vous pouvez définir l'argument en faisant glisser l'objet de la fenêtre Base de données vers la zone d'argument Nom objet de l'action.
- Tapez un commentaire concernant l'action. Les commentaires sont facultatifs.
- Pour ajouter des actions supplémentaires à la macro, placez-vous sur une autre ligne d'action et répétez l'étape 3. Access exécute les actions dans l'ordre où vous les entrez.
Créer un groupe de macros
Si vous souhaitez regrouper plusieurs macros associées dans un même emplacement au lieu de les mémoriser séparément, vous pouvez les organiser sous la forme d'un groupe de macros.- Dans la fenêtre Base de données, sous Objets, cliquez sur Macros .
- Cliquez sur le bouton Nouveau de la barre d'outils de la fenêtre Base de données.
- Cliquez sur le bouton Noms de macro de la barre d'outils s'il n'est pas déjà enfoncé.
- Dans la colonne Nom de macro, attribuez un nom à la première macro du groupe de macros.
- Ajoutez les
actions que vous souhaitez que la macro exécute.
- Dans la fenêtre Macro, cliquez sur la première ligne vide de la colonne Action. Si vous souhaitez insérer une action entre deux lignes d'action, cliquez sur le sélecteur de la ligne d'action située directement sous la ligne où vous souhaitez insérer la nouvelle action, puis cliquez sur Insérer une ligne dans la barre d'outils.
- Dans la colonne Action, cliquez sur la flèche pour afficher la liste d'actions.
- Cliquez sur l'action que vous voulez utiliser.
- Dans la partie inférieure de la fenêtre, spécifiez les arguments de l'action, si nécessaire. Dans le cas d'arguments d'action dont la définition correspond à un nom d'objet de base de données, vous pouvez définir l'argument en faisant glisser l'objet de la fenêtre Base de données vers la zone d'argument Nom objet de l'action.
- Tapez un commentaire concernant l'action. Les commentaires sont facultatifs.
- Répétez les étapes 4 et 5 pour toutes les autres macros que vous voulez inclure dans le groupe de macros.
Remarques
- Lorsque vous exécutez un groupe de macros, Access exécute chaque macro, en commençant par la première action, jusqu'à ce qu'il rencontre une action ArrêtMacro, un autre nom de groupe de macros ou aucune autre action.
- Lorsque vous enregistrez le groupe de macros, le nom que vous spécifiez
correspond au nom du groupe de macros. Ce nom est affiché dans la liste de
macros et de groupes de macros qui figure dans la fenêtre Base de données.
Chaque fois que vous faites référence à une macro d'un groupe de macros,
utilisez la syntaxe suivante :
nomgroupemacro.nommacro
- Exécuter une macro
Vous pouvez exécuter directement une
macro, dans un groupe de macros, à partir d'une autre macro ou d'une
procédure événementielle, ou en réponse à un
événement se produisant sur un formulaire, un état ou un
contrôle sur un formulaire ou un état.
Exécuter une macro
Pour exécuter directement une macro, effectuez l'une des opérations suivantes :- Pour exécuter une macro à partir de la fenêtre Macro, cliquez sur Exécuter dans la barre d'outils.
- Pour exécuter une macro à partir de la fenêtre Base de données, cliquez sur Macros, puis double-cliquez sur un nom de macro.
- Sur le menu Outils, pointez sur Macro, cliquez Exécuter Macro, puis sélectionnez la macro dans la liste Nom de macro.
- Exécuter une macro à partir d'une procédure Microsoft Visual Basic en utilisant la méthode RunMacro ou l'objet DoCmd.
Exécuter une macro située dans un groupe de macros
Pour exécuter une macro appartenant à un groupe de macros, effectuez l'une des opérations suivantes :- Spécifiez une macro comme un paramètre de
propriété événementielle dans un formulaire ou un état, ou comme
l'argument Nom macro de l'action ExécuterMacro. Utilisez la syntaxe
ci-dessous lorsque vous faites référence à la macro:
nomgroupemacro.nommacro
Par exemple, ce paramètre de propriété événementielle permet d'exécuter une macro appelée Catégories dans un groupe de macros appelé Boutons Menus des Formulaires.
Boutons Menus des Formulaires.Catégories
- Sur le menu Outils, pointez sur Macro, cliquez Exécuter Macro, puis sélectionnez la macro dans la liste Nom de macro. Quand apparaît une liste de noms de macros, Microsoft Access y met une entrée pour chaque macro de chaque groupe de macros sous la forme nomgroupemacro.nommacro.
- Exécutez une macro appartenant à un groupe de macros à partir d'une procédure Visual Basic en utilisant la méthode ExécuterMacro de l'objet DoCmd, en fonction de la syntaxe décrite précédemment pour faire référence à la macro.
Exécuter une macro à partir d'une autre macro ou d'une procédure Visual Basic
Ajoutez l'action ExécuterMacro à votre macro ou procédure.- Pour ajouter l'action ExécuterMacro à une macro, cliquez sur ExécuterMacro dans la liste d'actions dans une ligne d'action vierge, puis définissez l'argument Nom de macro en fonction du nom de la macro que vous voulez exécuter.
- Pour ajouter l'action ExécuterMacro à une procédure
Visual Basic , ajoutez la méthode RunMacro de l'objet
DoCmd à votre procédure, puis spécifiez le nom de la macro
que vous souhaitez exécuter ; par exemple, la méthode RunMacro
suivante exécute la macro appelée Ma Macro :
DoCmd.RunMacro "My Macro"
Exécuter une macro ou une procédure événementielle en réponse à un événement sur un formulaire, un état ou un contrôle
Microsoft Access répond à de nombreux types d'événements de formulaire, d'état et de contrôle, notamment les clics de souris, les modifications des données et l'ouverture ou la fermeture des formulaires ou états.- Ouvrez le formulaire ou l'état en mode Création.
- Affichez la feuille des propriétés du formulaire ou de l'état ou d'une section ou d'un contrôle du formulaire ou de l'état.
- Cliquez sur l'onglet Événement.
- Cliquez sur la propriété de type événement de l'événement qui doit déclencher la procédure. Pour afficher, par exemple, la procédure événementielle de l'événement Changement, cliquez sur la propriété SurChangement (OnChange).
- Cliquez sur Générer en regard de la zone de propriété pour afficher la boîte de dialogue Choisir Générateur.
- Effectuez l'une des actions suivantes :
- Créer la macro
- Créer une procédure événementielle
- L'enregistrement de la macro ou de la procédure attribuera à la
propriété de type événement appropriée le nom de la macro ou
[Procédure événementielle] si vous utilisez une procédure
événementielle.
Par exemple, pour utiliser une macro afin d'afficher un message lorsque vous cliquez sur un bouton de commande, attribuez à la propriété SurClic de ce bouton de commande le nom d'une macro qui affiche le message. Pour utiliser une procédure événementielle, créez une procédure événementielle Clic pour le bouton de commande, puis attribuez la valeur [Procédure événementielle] à sa propriété SurClic.
- Localiser les problèmes d'une macro en l'exécutant pas-à-pas
En exécutant une macro pas à pas, vous
pouvez suivre le déroulement de la macro et le résultat de chaque action, ce qui permet
d'isoler les actions qui engendrent une erreur ou des résultats
indésirables.
- Ouvrez la macro.
- Dans la fenêtre Base de données, sous Objets, cliquez sur Macros
- Cliquez sur le nom de la macro que vous souhaitez ouvrir.
- Cliquez sur le bouton Modifier de la barre d'outils de la fenêtre Base de données.
- Cliquez sur Pas à pas dans la barre d'outils.
- Cliquez sur Exécuter dans la barre d'outils.
- Effectuez l'une des actions suivantes :
- Pour exécuter l'action affichée dans la boîte de dialogue Pas à
pas, cliquez sur Pas à pas.
Pour interrompre l'exécution de la macro et fermer la boîte de dialogue, cliquez sur Arrêter. - Pour désactiver la procédure pas-à-pas et exécuter les actions restantes de la macro, cliquez sur Continuer.
- Pour exécuter l'action affichée dans la boîte de dialogue Pas à
pas, cliquez sur Pas à pas.
Vous pouvez également interrompre une macro en cours d'exécution et poursuivre l'exécution selon la procédure pas-à-pas en appuyant sur CTRL+PAUSE.
- Impression d'un état à partir d'un
formulaire
Vous pouvez automatiser la manière dont un utilisateur imprime un état en
effectuant les actions OuvrirFormulaire et Imprimer dans une macro. Vous pouvez,
par exemple, permettre à un utilisateur d'imprimer un rapport en cliquant sur le
bouton d'un formulaire, en choisissant une commande à partir d'un menu
personnalisé ou en appuyant sur une combinaison de touches.
Utilisez l'action OuvrirFormulaire si vous voulez restreindre le nombre d'enregistrements à imprimer, ou si vous voulez ouvrir un état dans l'Aperçu avant impression. Lorsque vous utilisez l'action OuvrirFormulaire afin d'imprimer un état, Access imprime le état à l'aide des paramètres par défaut de la boîte de dialogue Imprimer.
Utilisez l'action Imprimer pour définir les options d'impression avant d'imprimer votre état. L'action Imprimer contient des arguments pour chaque option de la boîte de dialogue Imprimer. - Conditions dans une macro On peut créer une macro dont certaines actions ne s'éxécute qu'à certaines conditions, en utilisant l'icône condition de la barre d'outils macro
- Macros ou Visual Basic
Dans Access, vous pouvez accomplir
de nombreuses tâches à l'aide de
macros ou au moyen de l'interface utilisateur. Dans de nombreux autres
programmes de base de données, pour accomplir les mêmes tâches vous devez
recourir à la programmation. Utiliser une macro ou
Visual Basic Applications dépend souvent de ce que vous
voulez faire.
À quel moment dois-je utiliser une macro ?
Les macros représentent une manière facile de s'occuper de détails simples, tels que l'ouverture et la fermeture de formulaires, et l'exécution d'états. Vous pouvez aisément et rapidement lier ensemble les objets de base de données que vous avez créés parce que vous ne devez vous souvenir que de peu de syntaxe ; les arguments de chaque action sont affichés dans la partie inférieure de la fenêtre Macro.
En plus de la facilité d'utilisation qu'offrent les macros, vous devez les utiliser pour :- Effectuer des affectations de touche générales.
- Exécuter une action ou une série d'actions à l'ouverture d'une base de données. Vous pouvez toutefois utiliser la boîte de dialogue de démarrage pour que des actions soient exécutées à l'ouverture de la base de données, telles que l'ouverture d'un formulaire.
À quel moment dois-je utiliser Visual Basic ?
Vous devez utiliser Visual Basic à la place de macros si vous voulez :- Faciliter la maintenance de votre base de données. Étant donné que les macros sont des objets différents des formulaires et états qui les utilisent, il peut être difficile d'assurer la maintenance d'une base de données contenant des macros qui répondent aux événements des formulaires et des états. Par contre, les procédures événementielles Visual Basic sont intégrées dans la définition du formulaire ou de l'état. Si vous déplacez un formulaire ou un état d'une base de données à une autre, les procédures événementielles qui y sont intégrées se déplacent en même temps.
- Utilisez des fonctions intégrées ou créez les vôtres. Access renferme de nombreuses fonctions intégrées, telles que la fonction IPmt, qui calcule le montant de l'intérêt. Vous pouvez utiliser ces fonctions pour effectuer des calculs sans avoir à créer des expressions complexes. À l'aide de Visual Basic, vous pouvez également créer vos propres fonctions soit pour effectuer des calculs qui excèdent la capacité d'une expression, soit pour remplacer des expressions complexes. De plus, vous pouvez utiliser les fonctions que vous créez dans des expressions pour appliquer une opération courante à plusieurs objets.
- Messages d'erreur d'identificateur. Lorsqu'un événement inattendu survient alors qu'un utilisateur travaille dans votre base de données et qu'Access affiche un message d'erreur, ce message peut paraître incompréhensible pour l'utilisateur, surtout si ce dernier n'est pas un utilisateur averti d'Access. À l'aide de Visual Basic, vous pouvez détecter l'erreur quand elle survient et, soit afficher votre propre message, soit entreprendre une action.
- Créer ou manipuler des objets. Dans la majorité des cas, vous vous apercevrez qu'il est plus facile de créer et de modifier un objet dans son mode Création. Toutefois, il se peut que vous vouliez parfois manipuler la définition d'un objet dans du code. À l'aide de Visual Basic, vous pouvez manipuler tous les objets dans une base de données, ainsi que la base de données elle-même.
- Accomplir des actions au niveau du système. Vous pouvez exécuter l'action ExécuterApplication dans une macro pour exécuter une autre application Microsoft Windows ou Microsoft MS-DOS depuis votre application, mais une macro ne vous permet d'accomplir pratiquement rien d'autre à l'extérieur d'Access. À l'aide de Visual Basic, vous pouvez vérifier si un fichier existe sur le système, utiliser l'Automatisation ou l'échange dynamique des données (DDE) pour communiquer avec d'autres applications tournant sous Windows, telles que Microsoft Excel, et vous pouvez appeler des fonctions dans les DLL (bibliothèques de liaison dynamiques de Windows.
- Manipuler un enregistrement à la fois. Visual Basic vous permet de parcourir les enregistrements d'un jeu d'enregistrements un par un et d'accomplir une action sur chaque enregistrement. Par opposition, les macros ne manipulent les enregistrements que par jeu entier d'enregistrements.
- Passer des arguments à vos procédures Visual Basic. Vous pouvez définir des arguments pour les actions de macro dans la partie inférieure de la fenêtre Macro lorsque vous créez la macro, mais vous ne pouvez pas les modifier lors de l'exécution de la macro. Avec Visual Basic, par contre, vous pouvez passer des arguments à votre code en cours d'exécution ou vous pouvez utiliser des variables comme arguments, ce que vous ne pouvez pas effectuer dans des macros. Vous bénéficiez ainsi d'une très grande souplesse d'utilisation de vos procédures Visual Basic.
- Sécurité
Lorsque vous vous connectez sur une base de donnée, Access ouvre automatiquement un groupe de travail. Ce groupe de travail définit des utilisateurs et des groupes d'utilisateurs. Un utilisateur se connecte grâce à un login (compte utilisateur) et un mot de passe. Chaque utilisateur est repris dans un groupe d'utilisateurs qui rassemble les utilisateurs de même profil. Les membres d'un même groupe ont les mêmes droits. Lorsqu'une sécurité au niveau utilisateur est mise en oeuvre, l'accès à la base de données passe par un mot de passe au démarrage. Microsoft Access lit alors le fichier de groupe de travail qui inclut les droits d'accès de chacun. C'est la solution standard de sécurité en réseau.
Remarque: si vous ne créez pas de profils utilisateurs, vous êtes automatiquement connecté dans un groupe de travail par défaut en tant qu'administrateur. Vous avez dans ce cas tous les droits d'accès.
La majorité des commandes pour sécuriser une base de donnée Access se trouvent dans le menu outils, sous la commande sécurité.
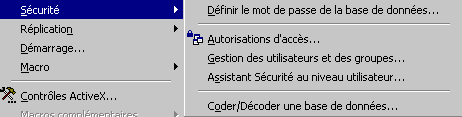
Avant d'appliquer les droits et accès, faites une copie de votre base de donnée. Certains manipulations peuvent bloquer l'accès à votre base de donnée.
Il existe différents niveaux d'utilisateurs, ayant différents droits sur les objets de la base de données.
Les administrateurs ont toutes les autorisations, y compris droit d'accès, effacer les fichiers, .... Un utilisateur qui crée un objet (une table ou un formulaire par exemple) est propriétaire de ses fichiers. Il a donc le droit non seulement de les modifier, supprimer, mais également de déléguer des droits aux autres utilisateurs. Vous pouvez néanmoins changer le propriétaire par le deuxième onglet. Remarque, ceci est créé pour chaque objets. Changer le propriétaire d'une base de donnée existante est relativement fastidieux.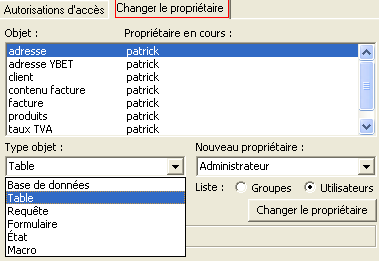
Le premier onglet permet de donner les autorisations sur chaque objet de la base de donnée.
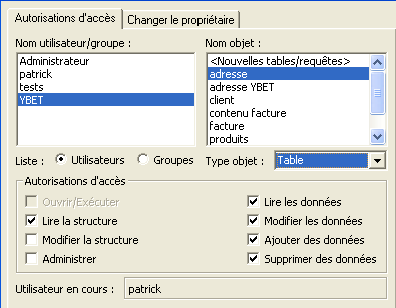
Les possibilités sont:
- Ouvrir / Exécuter: permet d'ouvrir un formulaire / état / macro.
- Lire la structure permet de lire la structure des tables, requêtes, ... (taille des champs par exemple), mais pas de les modifier. Cette fonction est nécessaire pour pouvoir lire les données.
- Modifier la structure permet de modifier les champs, taille, ... Y compris effacer l'objet.
- Administrer permet de donner des droits à d'autres utilisateurs. Le propriétaire est d'office administrateur de ses objets.
- Lire les données permet de lire les informations
- Modifier les données permet de lire et de modifier les données dans l'objet.
- Ajouter des données permet d'ajouter des champs dans la base de donnée.
- Supprimer des données permet de supprimer le contenu de champs et d'enregistrements.
Vous pouvez sélectionnez plusieurs objets d'un coups. Pour les groupes et utilisateurs, songez à donner des autorisations d'accès aux nouveaux objets. Ceci vous évitera de le faire manuellement ensuite.