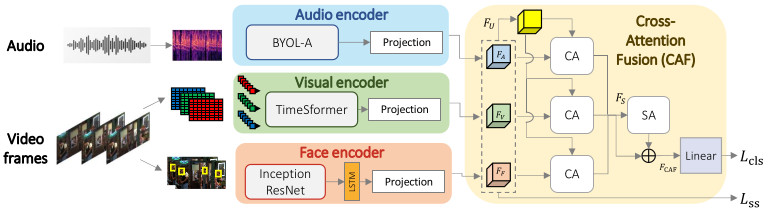
Automatically understanding funny moments (i.e., the moments that make people laugh) when
watching
comedy is challenging, as they relate to various features, such as facial expression, body
language,
dialogues and culture. In this paper, we propose FunnyNet, a model that relies on cross- and
self-attention for both visual and audio data to predict funny moments in videos. Unlike most
methods
that focus on text with or without visual data to identify funny moments, in this work in
addition
to
visual cues, we exploit audio. Audio comes naturally with videos, and moreover it contains
higher-level
cues associated with funny moments, such as intonation, pitch and pauses.
To acquire labels for training, we propose an unsupervised approach that spots and labels funny
audio
moments.
We provide experiments on five datasets: the sitcoms TBBT, MHD, MUStARD, Friends, and the TED
talk
UR-Funny.
Extensive experiments and analysis show that FunnyNet successfully exploits visual and auditory
cues
to
identify funny moments, while our findings corroborate our claim that audio is more suitable
than
text
for funny moment prediction. FunnyNet sets the new state of the art for laughter detection with
audiovisual or multimodal cues on all datasets.