| ||||||
Jury:
|
||||||
|
Abstract
As the number of Internet activities increases, there is a growing amount of personal information about the users that is transferred using public electronic means, making it feasible to collect a huge amount of information about a person. As a consequence, the need for mechanisms to protect such information is compelling. In this thesis, we study security protocols with an emphasis on the property of anonymity and we propose methods to express and verify this property. Anonymity protocols often use randomization to introduce noise, thus limiting the inference power of a malicious observer. We consider a probabilistic framework in which a protocol is described by its set of anonymous information, observable information and the conditional probability of observing the latter given the former. In this framework we express two anonymity properties, namely strong anonymity and probable innocence. Then we aim at quantitative definitions of anonymity. We view protocols as noisy channels in the information-theoretic sense and we express their degree of anonymity as the converse of channel capacity. We apply this definition to two known anonymity protocols. We develop a monotonicity principle for the capacity, and use it to show a number of results for binary channels in the context of algebraic information theory. We then study the probability of error for the attacker in the context of Bayesian inference, showing that it is a piecewise linear function and using this fact to improve known bounds from the literature. Finally we study a problem that arises when we combine probabilities with nondeterminism, where the scheduler is too powerful even for trivially secure protocols. We propose a process calculus which allows to express restrictions to the scheduler, and we use it in the analysis of an anonymity and a contract-signing protocol. |
||||||
|
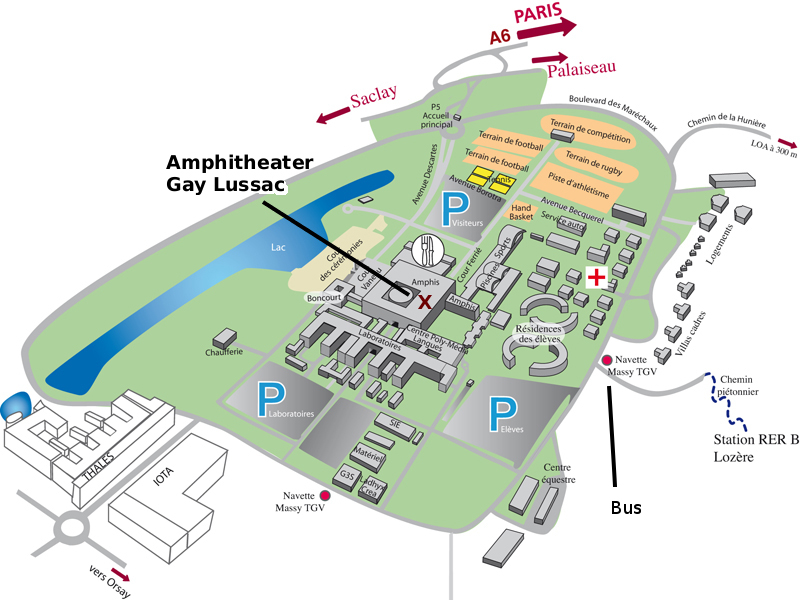
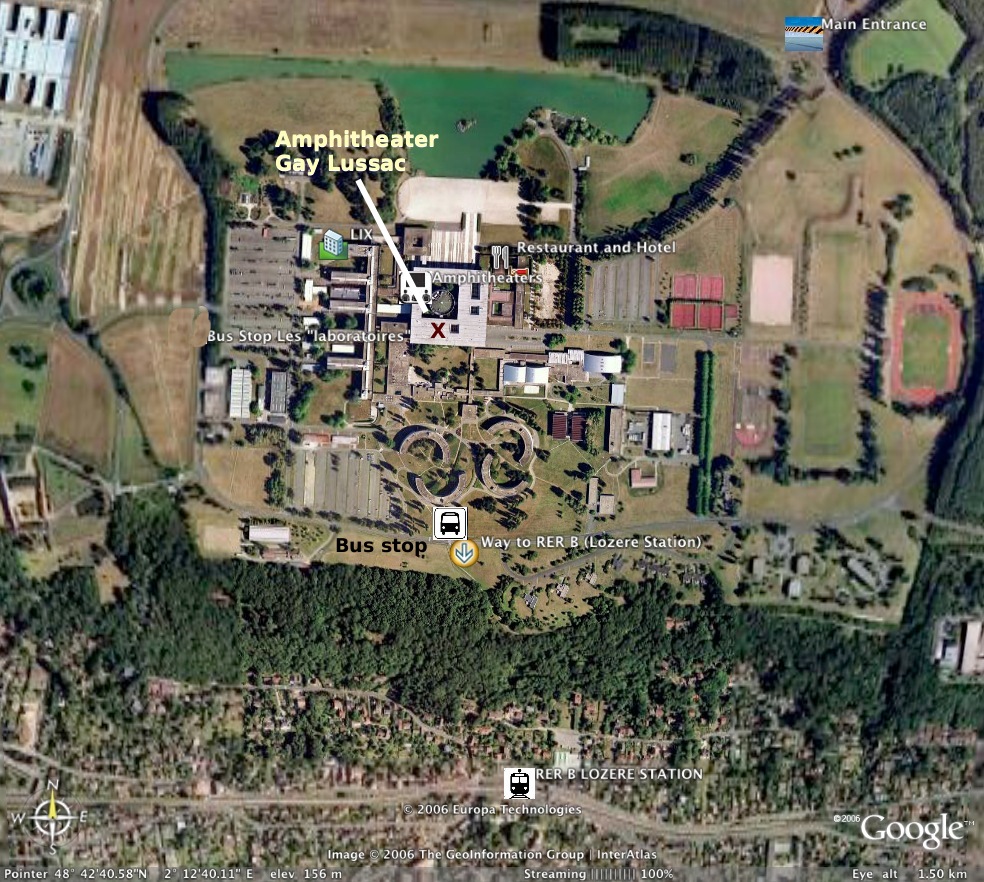
How to reach the defense
How to reach the campus
More information is also available here. |
{kind=link}
{kind=link}
{kind=link}